爬虫
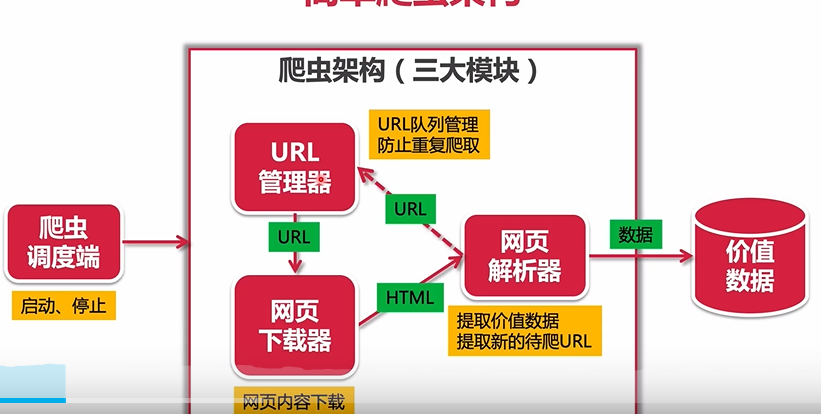
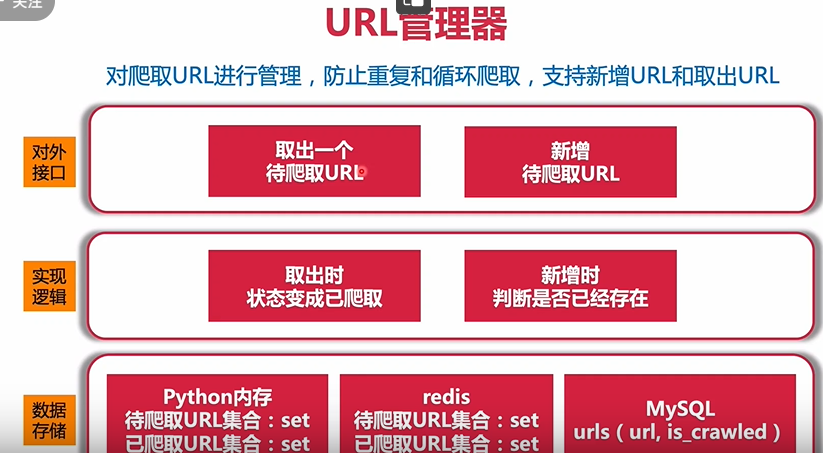
URL管理器
管理带爬取URL
设立优先级 循环爬取 重复爬取等问题
网页解析器
提取价值数据
提取新的待爬URL
网页下载器
网页内容下载
requests
正确的encoding才能正确的解析网页
r.url显示的是编码后的url
与输入的不同
r.text是字符型的返回
url是字节型的返回
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import requests >>> url="http://www.crazyant.net" >>> r=requets.get(url) Traceback (most recent call last): File "<stdin>", line 1, in <module> NameError: name 'requets' is not defined >>> r=requests.get(url) >>> r.status_code 200 >>> r.headers {'Server': 'nginx', 'Date': 'Fri, 11 Aug 2023 14:36:41 GMT', 'Content-Type': 'text/ html; charset=UTF-8', 'Transfer-Encoding': 'chunked', 'Connection': 'keep-alive', ' Vary': 'Accept-Encoding', 'X-UA-Compatible': 'IE=edge', 'Link': '<http://www.crazyant.net/wp-json/>; rel="https://api.w.org/"', 'Content-Encoding': 'gzip'} >>> r.cookies <RequestsCookieJar[]>
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 url="http://www.baidu.com" >>> r=requests.get(url) >>> r.status_code 200 >>> r.encoding 'ISO-8859-1' >>> r.headers {'Cache-Control': 'private, no-cache, no-store, proxy-revalidate, no-transform', 'C onnection': 'keep-alive', 'Content-Encoding': 'gzip', 'Content-Type': 'text/html', 'Date': 'Fri, 11 Aug 2023 14:51:59 GMT', 'Last-Modified': 'Mon, 23 Jan 2017 13:27:3 6 GMT', 'Pragma': 'no-cache', 'Server': 'bfe/1.0.8.18', 'Set-Cookie': 'BDORZ=27315; max-age=86400; domain=.baidu.com; path=/', 'Transfer-Encoding': 'chunked'} >>> r.cookies <RequestsCookieJar[Cookie(version=0, name='BDORZ', value='27315', port=None, port_s pecified=False, domain='.baidu.com', domain_specified=True, domain_initial_dot=True , path='/', path_specified=True, secure=False, expires=1691851919, discard=False, comment=None, comment_url=None, rest={}, rfc2109=False)]>
headers中没有返回content—type
requests默认认为其是ISO-8859-1
r.text返回的中文有乱码
查看网页源码 判断其编码方式
r.encoding=”utf-8”
然后再看其text
中文信息正常返回
url管理器
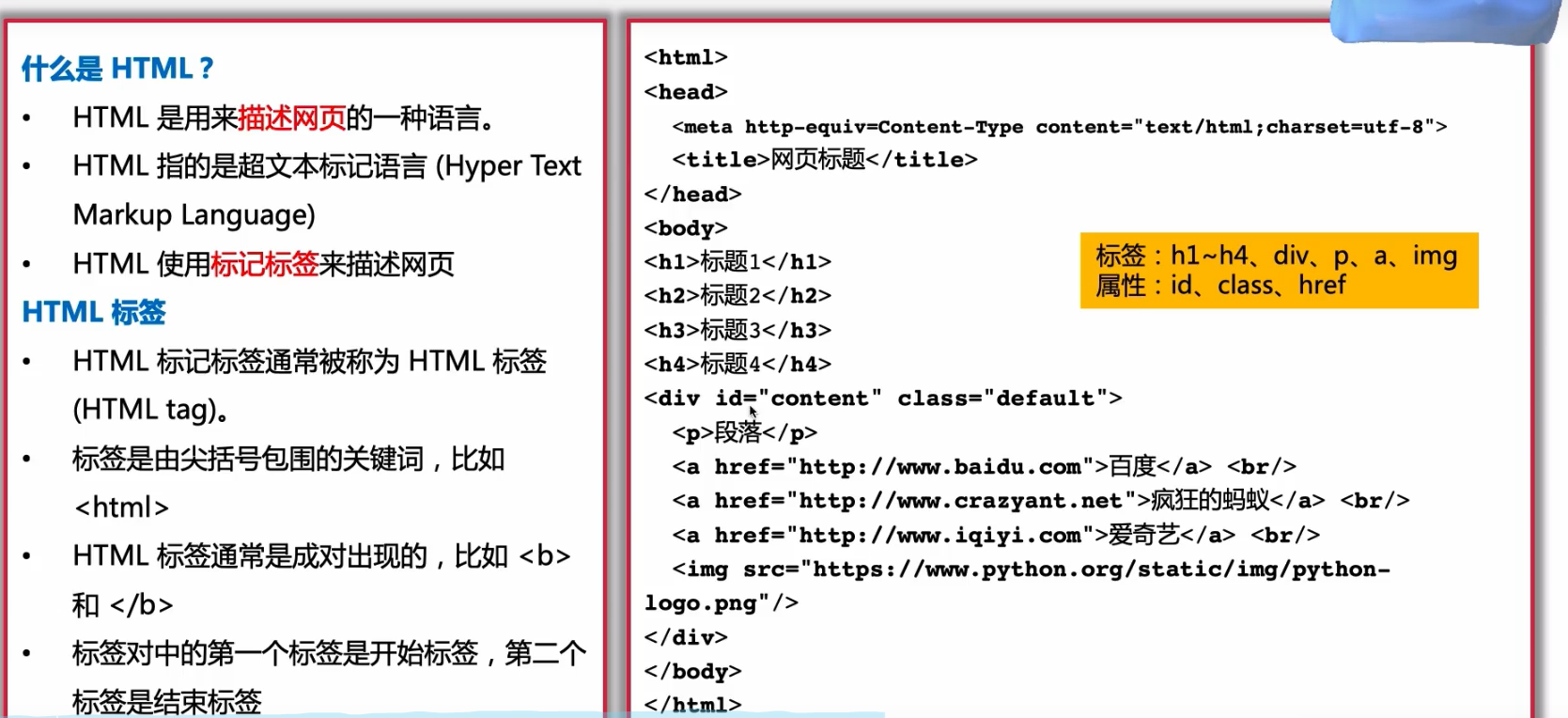
html简介
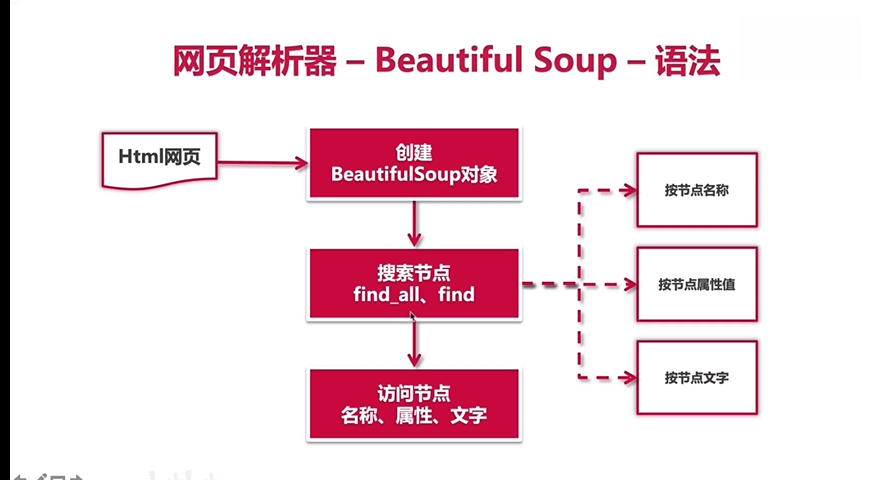
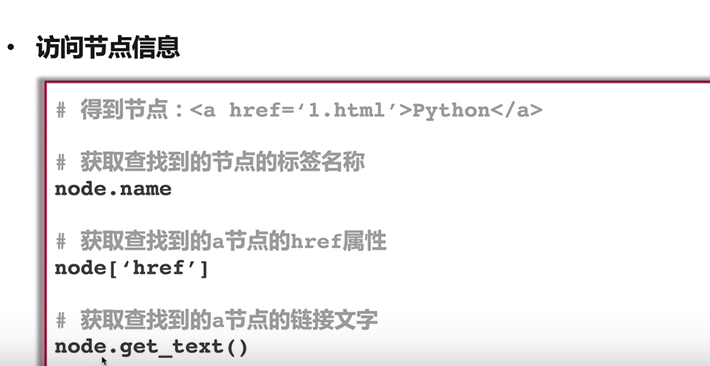
bs
1 2 3 4 5 6 7 8 9 10 11 from bs4 import BeautifulSoup with open("./test.html",encoding="utf-8") as fin: html_doc=fin.read() soup=BeautifulSoup(html_doc,"html.parser") links=soup.find_all("a") for link in links: print(link.name,link["href"],link.get_text()) #名称 属性:id class href 文字
1 2 3 a baidu.com baidu a bilibili.com bilibili a fffjay.fun fffjay
id属性是全局唯一的
可以通过查找id定位到段落,减小查询范围,加快寻找效率
如下
1 2 3 4 5 6 7 8 9 10 11 12 from bs4 import BeautifulSoup with open("./test.html",encoding="utf-8") as fin: html_doc=fin.read() soup=BeautifulSoup(html_doc,"html.parser") div_node=soup.find("div",id="content") print(div_node) print("#"*30) links=div_node.find_all("a") for link in links: print(link.name,link["href"],link.get_text())
1 2 3 4 5 6 7 8 9 10 <div class="default" id="content"> <p>passage</p> <a href="baidu.com"> baidu</a><br/> <a href="bilibili.com"> bilibili</a><br/> <a href="fffjay.fun">fffjay</a><br/> </div> ############################## a baidu.com baidu a bilibili.com bilibili a fffjay.fun fffjay
分析目标 1 查看网页源代码
2 检查
elements 展示给用户的源代码 经JavaScript加载后的
对于这种动态的网页,采用s
network 类似于抓包 选择doc模块
实战1爬自己博客的tag 1 2 3 4 5 6 7 8 9 10 11 12 13 url="http://fffjay.fun/" import requests r=requests.get(url) if r.status_code!=200: raise Exception() html_doc=r.text from bs4 import BeautifulSoup soup=BeautifulSoup(html_doc,"html.parser") h2_node=soup.find_all(class_="menus_item" ) for nodes in h2_node: link=nodes.find("a") print(link["href"],link.get_text)
1 2 3 4 5 6 7 8 9 10 11 12 ound method PageElement.get_text of <a class="site-page" href="/"><i class="fa-fw fas fa-home"></i><span> 首页</span></a>> /archives/ <bound method PageElement.get_text of <a class="site-page" href="/archives/"><i class="fa-fw fas fa-archive"></i><span> 时间轴</span></a>> /tags/ <bound method PageElement.get_text of <a class="site-page" href="/tags/"><i class="fa-fw fas fa-tags"></i><span> 标签</span></a>> /categories/ <bound method PageElement.get_text of <a class="site-page" href="/categories/"><i class="fa-fw fas fa-folder-open"></i><span> 分类</span></a>> /link/ <bound method PageElement.get_text of <a class="site-page" href="/link/"><i class="fa-fw fas fa-link"></i><span> 友链</span></a>> /about/ <bound method PageElement.get_text of <a class="site-page" href="/about/"><i class="fa-fw fas fa-heart"></i><span> 关于</span></a>> / <bound method PageElement.get_text of <a class="site-page" href="/"><i class="fa-fw fas fa-home"></i><span> 首页</span></a>> /archives/ <bound method PageElement.get_text of <a class="site-page" href="/archives/"><i class="fa-fw fas fa-archive"></i><span> 时间轴</span></a>> /tags/ <bound method PageElement.get_text of <a class="site-page" href="/tags/"><i class="fa-fw fas fa-tags"></i><span> 标签</span></a>> /categories/ <bound method PageElement.get_text of <a class="site-page" href="/categories/"><i class="fa-fw fas fa-folder-open"></i><span> 分类</span></a>> /link/ <bound method PageElement.get_text of <a class="site-page" href="/link/"><i class="fa-fw fas fa-link"></i><span> 友链</span></a>> /about/ <bound method PageElement.get_text of <a class="site-page" href="/about/"><i class="fa-fw fas fa-heart"></i><span> 关于</span></a>>
也不知道算成功吗。。
1 2 3 4 5 6 7 8 9 10 11 12 13 url="http://fffjay.fun/" import requests r=requests.get(url) if r.status_code!=200: raise Exception() html_doc=r.text from bs4 import BeautifulSoup soup=BeautifulSoup(html_doc,"html.parser") h2_node=soup.find_all(class_="menus_item" ) for nodes in h2_node: link=nodes.find("a") print("http://fffjay.fun/"+link["href"],)
修改后
成功力
1 2 3 4 5 6 7 8 9 10 11 12 13 14 http://fffjay.fun// http://fffjay.fun//archives/ http://fffjay.fun//tags/ http://fffjay.fun//categories/ http://fffjay.fun//link/ http://fffjay.fun//about/ http://fffjay.fun// http://fffjay.fun//archives/ http://fffjay.fun//tags/ http://fffjay.fun//categories/ http://fffjay.fun//link/ http://fffjay.fun//about/
实战2爬取博客网站全部文章列表 还是爬我自己
\d代表数字
\d+代表多个数字
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 from utils import url_manager import requests from bs4 import BeautifulSoup import re url="http://www.crazyant.net/" urls=url_manager.UrLManager() urls.add_new_url(url) fout=open("craw_all_pages.txt","w") while urls.has_new_url(): curr_url=urls.get_url() r=requests.get(curr_url,timeout=3)#三秒不返回结果就跳过 if r.status_code!=200: print("error") continue soup=BeautifulSoup(r.text,"html.parser") title=soup.title.string fout.write("%s\t%s\n"%(curr_url,title)) fout.flush() #fout.write("%s\t%s\n" % (curr_url, title)) print("嘻嘻: %s,%s,%d"%(curr_url,title,len(urls.new_urls))) links=soup.find_all("a") for link in links: href=link["href"] pattern=r'^http://www.crazyant.net/\d+.html$' if re.match(pattern,href): urls.add_new_url(href) fout.close()
爬我自己的方法不同,还是爬作者的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 from utils import url_manager import requests from bs4 import BeautifulSoup import re url="http://www.crazyant.net/" urls=url_manager.UrLManager() urls.add_new_url(url) fout=open("craw_all_pages.txt","w") while urls.has_new_url(): curr_url=urls.get_url() r=requests.get(curr_url,timeout=3)#三秒不返回结果就跳过 if r.status_code!=200: print("error") continue soup=BeautifulSoup(r.text,"html.parser") title=soup.title.string fout.write("%s\t%s\n"%(curr_url,title)) fout.flush() #fout.write("%s\t%s\n" % (curr_url, title)) print("嘻嘻: %s,%s,%d"%(curr_url,title,len(urls.new_urls))) links=soup.find_all("a")#此处其实只来一次,一并将所需url打入管理器 for link in links: href=link["href"] pattern=r'^http://www.crazyant.net/\d+.html$' if re.match(pattern,href): urls.add_new_url(href) fout.close()
成功
实战三 豆瓣电影top 1 爬取网页
2soup解析数据
3借助panda将数据写出到excel
退役,我才刚学,结果人家网站做反爬了
实战4 历史天气 1 https://tianqi.2345.com/wea_history/54511.htm
发现不论选哪年的
url不改变说明是动态网页
要抓包分析
右键选择检查 观察网络板块
发现其有ua反爬机制
1 2 3 4 5 6 7 8 9 10 11 12 13 14 url="https://tianqi.2345.com/Pc/GetHistory" payload={ "areaInfo[areaId]": 54511, "areaInfo[areaType]": 2, "date[year]": 2015, "date[month]": 6 } headers={ "User-Agent":'''Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36 Edg/115.0.1901.203''' }#防止ua中有双引号发生冲突,直接三引号 import requests resp=requests.get(url,headers=headers,params=payload) print(resp.status_code) print(resp.text)
初步成功
1 2 200 {"code":1,"msg":"","data":"<ul class=\"history-msg\">\n ....
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 url="https://tianqi.2345.com/Pc/GetHistory" payload={ "areaInfo[areaId]": 54511, "areaInfo[areaType]": 2, "date[year]": 2015, "date[month]": 6 } headers={ "User-Agent":'''Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36 Edg/115.0.1901.203''' }#防止ua中有双引号发生冲突,直接三引号 import requests import pandas as pd resp=requests.get(url,headers=headers,params=payload) print(resp.status_code) data=resp.json()["data"] #data frame df=pd.read_html(data) print(df)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 [ 日期 最高温 最低温 天气 风力风向 0 2015-06-01 周一 34° 23° 多云~阴 无持续风向~北风微风~3-4级 1 2015-06-02 周二 33° 17° 晴 北风~无持续风向4-5级~微风 2 2015-06-03 周三 32° 22° 多云~阴 无持续风向微风 3 2015-06-04 周四 23° 17° 雷雨~阴 无持续风向微风 4 2015-06-05 周五 32° 20° 多云~晴 无持续风向微风 5 2015-06-06 周六 32° 18° 雷雨~阴 无持续风向微风 6 2015-06-07 周日 29° 17° 雷雨~晴 无持续风向微风 7 2015-06-08 周一 32° 20° 晴~多云 无持续风向微风 8 2015-06-09 周二 29° 22° 阵雨~雷雨 无持续风向微风 9 2015-06-10 周三 25° 19° 雷雨 无持续风向微风 10 2015-06-11 周四 30° 18° 多云 北风~无持续风向3-4级~微风 11 2015-06-12 周五 29° 19° 多云 北风~无持续风向4-5级~微风 12 2015-06-13 周六 28° 17° 阵雨~多云 北风~无持续风向3-4级~微风 13 2015-06-14 周日 32° 19° 晴 无持续风向微风 14 2015-06-15 周一 32° 22° 多云 无持续风向微风 15 2015-06-16 周二 32° 22° 雷雨 无持续风向微风 16 2015-06-17 周三 32° 20° 雷雨~晴 无持续风向微风 17 2015-06-18 周四 32° 19° 多云~雷雨 北风~无持续风向3-4级~微风 18 2015-06-19 周五 26° 17° 雷雨~多云 无持续风向微风 19 2015-06-20 周六 32° 19° 晴 无持续风向微风 20 2015-06-21 周日 32° 21° 多云 无持续风向微风 21 2015-06-22 周一 31° 22° 多云~阵雨 无持续风向微风 22 2015-06-23 周二 29° 22° 雷雨~阴 无持续风向微风 23 2015-06-24 周三 29° 22° 阵雨~阴 无持续风向微风 24 2015-06-25 周四 28° 21° 雷雨 无持续风向微风 25 2015-06-26 周五 28° 21° 雷雨~阴 无持续风向微风 26 2015-06-27 周六 31° 22° 阴~多云 无持续风向微风 27 2015-06-28 周日 30° 24° 多云~阴 无持续风向微风 28 2015-06-29 周一 28° 21° 阵雨 北风~无持续风向3-4级~微风 29 2015-06-30 周二 28° 18° 阴~晴 无持续风向微风]
成功
接下来将该功能封装以爬取更多网页
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 url="https://tianqi.2345.com/Pc/GetHistory" headers={ "User-Agent":'''Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36 Edg/115.0.1901.203''' }#防止ua中有双引号发生冲突,直接三引号 import requests import pandas as pd def pa(year,month): # 提供年份和月份 payload = { "areaInfo[areaId]": 54511, "areaInfo[areaType]": 2, "date[year]": year, "date[month]": month } resp=requests.get(url,headers=headers,params=payload) print(resp.status_code) data=resp.json()["data"] #data frame df=pd.read_html(data) return df df=pa(2013,10) print(df)
捏码吗的,爬一个的时候没问题,封装起来后爬一个也没问题,但是一整合表格出问题了,搞了好久才明白
md不想了
df = pd.read_html(data)[0] # 解析 HTML 表格并转换为 DataFrame
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 url="https://tianqi.2345.com/Pc/GetHistory" headers={ "User-Agent":'''Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36 Edg/115.0.1901.203''' }#防止ua中有双引号发生冲突,直接三引号 import requests import pandas as pd def pa(year,month): # 提供年份和月份 payload = { "areaInfo[areaId]": 54511, "areaInfo[areaType]": 2, "date[year]": year, "date[month]": month } resp=requests.get(url,headers=headers,params=payload) print(resp.status_code) data=resp.json()["data"] #data frame df=pd.read_html(data)[0] return df df_list=[] for year in range(2011,2012): for month in range(1,13): print("”爬取“",year,month) df=pa(year,month) df_list.append(df) pd.concat(df_list).to_excel("beijing.xlsx",index=False)
最喜欢的环节 爬小说 1 2 3 4 5 6 7 8 9 10 11 12 13 14 import requests from bs4 import BeautifulSoup def get_novel_topic(): root_url="https://m.bbtxt8.com/book/89536/" r=requests.get(root_url) r.encoding="utf-8" soup=BeautifulSoup(r.text,"html.parser") for dd in soup.find_all("dd"): link=dd.find("a") if not link: continue print(link) get_novel_topic()
标题爬取成功
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 import requests from bs4 import BeautifulSoup import os # 获取小说章节链接和标题列表 def get_novel_topic(): root_url = "http://www.msxsw.com/35_35948/" r = requests.get(root_url) r.encoding = "gbk" soup = BeautifulSoup(r.text, "html.parser") data = [] for dd in soup.find_all("dd"): link = dd.find("a") data.append(("http://www.msxsw.com%s" % link["href"], link.get_text()))#二维数组 return data # 获取章节内容,添加容错处理 def get_chapter(url): r = requests.get(url) r.encoding = "gbk" soup = BeautifulSoup(r.text, "html.parser") content_div = soup.find("div", id="content") if content_div: return content_div.get_text() else: return "Chapter content not found" # 设置输出子目录 output_dir = os.path.join(os.path.dirname(__file__), "夜的命名树") if not os.path.exists(output_dir): os.makedirs(output_dir) # 遍历爬取章节并保存 for chapter in get_novel_topic(): url, title = chapter text = get_chapter(url).encode("utf-8") with open(os.path.join(output_dir, "%s.txt" % title), "wb") as font: font.write(text)
成功爬取笔趣阁小说
难点:编码text = get_chapter(url).encode(“utf-8”)
get_chapter(url) 函数返回的文本内容可能包含了一些在 UTF-8 编码下无法表示的字符
因此使用前要先编码
实战六 爬取图片