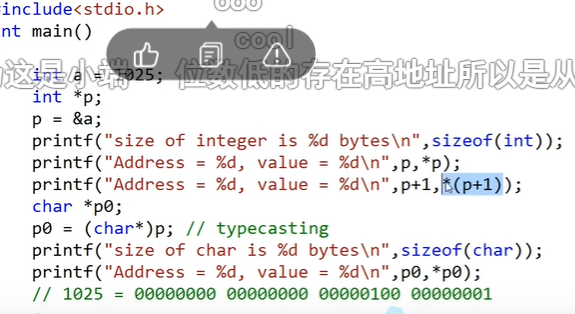
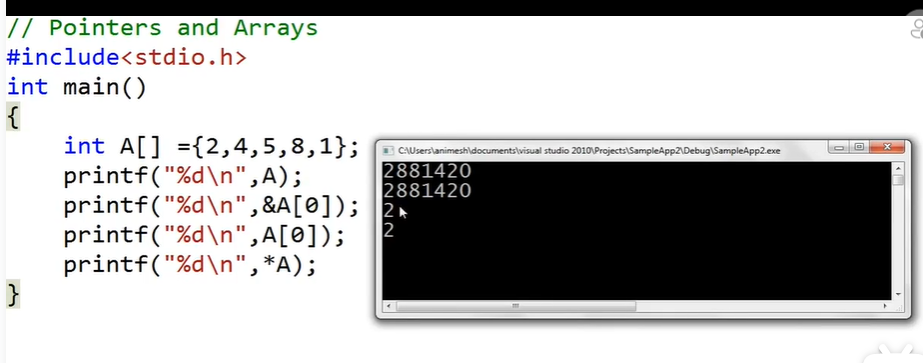
指针 1 2 3 int a=10; int* p=&a; int *p=&a;
下两行的效果是一样的
1 2 3 int a=10; int *p; p=&a;//我更喜欢这种写法,避免在我摆烂一段时间后看不懂
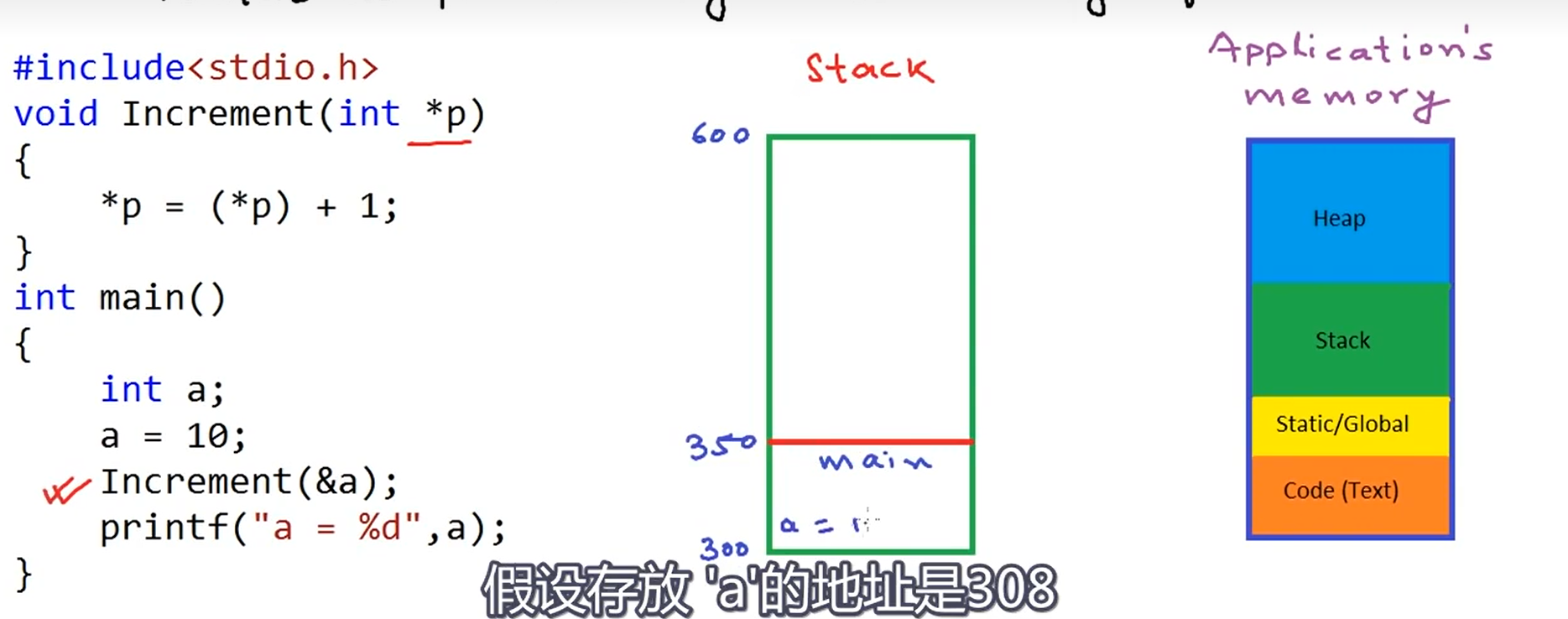
假设p=2002
p+1等于2006
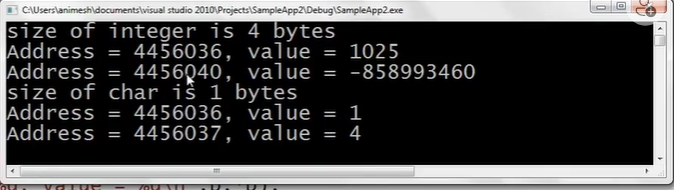
一个int型占四个字节,一个字节为1b,最近在学汇编,感觉知识都串通起来了
指针类型、算术运算、void指针
将1025转换成二进制并当作char型输出了,char占一字节,所以输出了最右边的2*1的零次方
p0+1指向的地址的值是4,00000100的值为4
void通用指针
void *p1;
p1=p;
有点类似拷贝文件要找到文件的地址,而不是只拷贝快捷方式
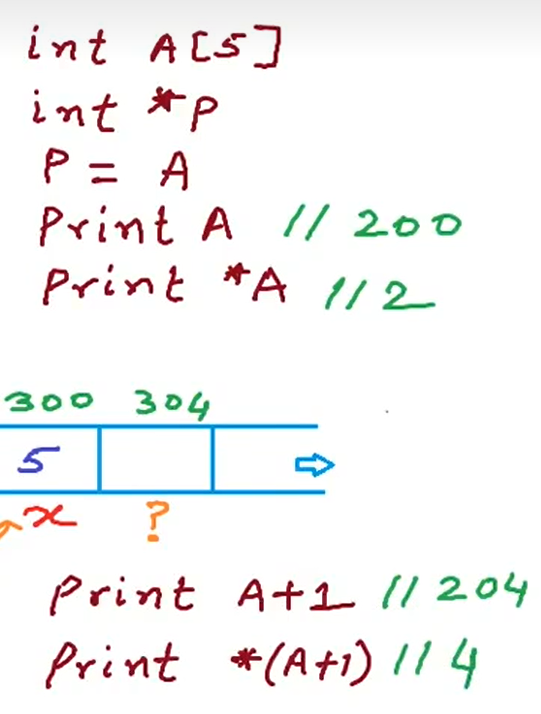
指针和数组
将p+1,由于数组的地址是连续的,在对p进行解引用,就能到达下一个数
这两种操作都能得到ai的地址
a[i]和 *a[i+1]
对a本身自增的操作非法
vector动态数组 (1)vector a 定义一个int类型的vector一维数组。
(2)vector a(10) 定义一个int类型的长度为十的vector一维数组。
(3)vector a(10)(1) 定义一个int类型的长度为十初值为一的vector一维数组。
(4)vector<vector > a 定义一个int类型的vector二维数组,要注意的是,在里面的vecotr后面要加一个空格,否则会被认为是移位运算符而编译错误。
(5)a.begin() 返回数组a的首元素的指针(迭代器)。
(6)a.end() 返回数组a的末尾元素的下一个元素的指针(迭代器)。
(7)a.size() 数组中的元素个数
(8)a.empty() 判断数组是否为空
(9)a.clear() 清空数组中的元素
(10)a.insert(a.begin(),1000) 将1000插入到向量a的起始位置前
(11)a.insert(a.begin(),3,1000); 将1000分别插入到向量元素位置的0-2处(共3个元素)
(12)a.erase(a.begin()); 将起始位置的元素删除
(13)a.erase(a.begin(),a.begin()+3) ; 将(a.begin(),a.begin()+3)之间的元素删除
(14)a.push_back(1) 将1放到数组尾部
(15)a[1] 数组中的下标为1的值
vector和数组相比,vector可以改变长度,清空的时间复杂度为O(1)。
例如及包柜一题中
1 2 if(bao[i].size()<=j) bao[i].resize(j+1);
提现了动态数组的特点
线性表 栈 1、栈(Stack)是一种线性存储结构,它具有如下特点:
(1)栈中的数据元素遵守“*先进后出*
(2)限定只能在栈顶进行插入和删除操作。
2、栈的相关概念:
(1)栈顶与栈底:允许元素插入与删除的一端称为栈顶,另一端称为栈底。
(2)压栈:栈的插入操作,叫做进栈,也称压栈、入栈。
(3)弹栈:栈的删除操作,也叫做出栈。
3、栈的常见分类:
(1)基于数组的栈——以数组为底层数据结构时,通常以数组头为栈底,数组头到数组尾为栈顶的生长方向
(2)基于单链表的栈——以链表为底层的数据结构时,以链表头为栈顶,便于节点的插入与删除,压栈产生的新节点将一直出现在链表的头部
使用标准库的栈时, 应包含相关头文件,在栈中应包含头文件: #include< stack > 。定义:stack< int > s;
1 2 3 4 5 s.empty(); //如果栈为空则返回true, 否则返回false; s.size(); //返回栈中元素的个数 s.top(); //返回栈顶元素, 但不删除该元素 s.pop(); //弹出栈顶元素, 但不返回其值 s.push(); //将元素压入栈顶
输出栈的最小值
使用一个辅助栈
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 #include <iostream> #include <stack> using namespace std; int main() { stack<int> date; stack<int> minn; int n; cin>>n; for(int i=1;i<=n;i++) { int a; cin>>a; date.push(a); if(minn.empty()) { minn.push(a); } if(!minn.empty()) { if(a<minn.top()) { minn.pop(); minn.push(a); } } } cout<<minn.top(); }
用链表实现栈 已知栈的特点为插入或删除元素的复杂度为O(1),但是链表的尾部插入或删除元素复杂度为O(n),所以应该从头部搞起,先创建一个新的节点,先把新节点的next设为head,再把head设为新节点,这两个步骤不能搞反,一旦反了,新节点就找不到头节点的位置了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 #include <stdio.h> #include <stdlib.h> struct node{ int data; struct node* link; }; struct node* top=NULL; void push(int x){ struct node* temp= (struct node*)malloc(sizeof(struct node*)); temp->data=x; temp->link=top; top=temp; } void pop(){ struct node *temp; if(top==NULL) return ; temp=top; top=top->link; free(temp); } void print() { struct node* temp=top;//使用临时变量防止修改头节点 while(temp!=NULL) { printf("%d",temp->data); temp=temp->link;//修改临时变量的地址来遍历链表 } printf("\n"); } int topp() { struct node* temp; temp=top; return temp->data; } int main() { push(3); //print(); int a=topp(); printf("%d",a); }
反转字符 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 #include <iostream> #include <stack> #include <cstring> using namespace std; void re(char *C,int n)//*C相当于C 【】,c中,数组是通过指针来传引用的 { stack<char> S; for(int i=0;i<n;i++) { S.push(C[i]); } for(int i=0;i<n;i++) { C[i]=S.top(); S.pop(); } } int main() { stack<char> a; a.push('H'); a.push('E'); a.push('L'); a.push('L'); a.push('O'); stack<int> b; printf("%c",a.top()); a.pop(); printf("%c",a.top()); a.pop(); printf("%c",a.top()); a.pop(); printf("%c",a.top()); a.pop(); printf("%c",a.top()); a.pop(); char C[66]; gets(C); re(C,strlen(C)); printf("%s",C); }
反转链表 括号匹配 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 #include <iostream> #include <stack> #include <cstring> using namespace std; int main() { stack<char> q; char a[10010]; scanf("%s",a); for(int i=0;i<strlen(a);i++) { if(a[i]=='{'||a[i]=='['||a[i]=='(') { q.push(a[i]); } if(a[i]==']'||a[i]==')'||a[i]=='}') { char b=q.top(); if(q.empty()==true) { cout<<"NO"; return 0; } if(q.top()=='{'&&a[i]=='}') { q.pop(); continue; } if(q.top()=='['&&a[i]==']') { q.pop(); continue; } if(q.top()=='('&&a[i]==')') { q.pop(); continue; } } } if(q.empty()!=true) { cout<<"NO"; return 0; } cout<<"YES"; return 0; }
队列 1、*队列(Queue)与栈一样,是一种线性存储结构,它具有如下特点:*
(1)队列中的数据元素遵循“先进先出 ”(First In First Out)的原则,简称FIFO 结构;
(2)在队尾添加元素,在队头删除元素。
2、队列的相关概念:
(1)队头与队尾: 允许元素插入的一端称为队尾,允许元素删除的一端称为队头;
(2)入队:队列 的插入操作;
(3)出队:队列的删除操作。
3、队列的操作:
(1)入队: 通常命名为push()
(2)出队: 通常命名为pop()
(3)求队列中元素个数
(4)判断队列是否为空
(5)获取队首元素
4、队列的分类:
(1)基于数组的循环队列(循环队列)
(2)基于链表的队列(链队列)
5、实例分析
C++队列queue模板类的定义在<queue>头文件中,queue 模板类需要两个模板参数,一个是元素类型,一个容器类型,元素类型是必要的,容器类型是可选的,默认为deque 类型。C++队列Queue是一种容器适配器,它给予程序员一种先进先出(FIFO)的数据结构。
那么我们如何判断队列是空队列还是已满呢?
a、栈空: 队首标志=队尾标志时,表示栈空。
b、栈满 : 队尾+1 = 队首时,表示栈满。
使用标准库的队列时, 应包含相关头文件,在栈中应包含头文件: #include< queue> 。定义:queue< int > q;
1 2 3 4 5 6 q.empty() 如果队列为空返回true,否则返回false q.size() 返回队列中元素的个数 q.pop() 删除队列首元素但不返回其值 q.front() 返回队首元素的值,但不删除该元素 q.push() 在队尾压入新元素 q.back() 返回队列尾元素的值,但不删除该元素
以数组作为底层数据结构时,一般讲队列实现为循环队列。这是因为队列在顺序存储上的不足:每次从数组头部删除元素(出队)后,需要将头部以后的所有元素往前移动一个位置,这是一个时间复杂度为O(n)的操作。
*C语言中,不能用动态分配的一维数组来实现循环队列,如果用户的应用程序中设有循环队列,则必须为它设定一个最大队列长度;如果用户无法预估所用队列的最大长度,则宜采用链队列。*
定义front为队列头元素的位置,rear为队列尾元素的位置,MAXSIZE为循环队列的最大长度。注意以下几点,循环队列迎刃而解:
A. 求元素的个数:(rear - front + MAXSIZE) % MAXSIZE
链表 以数组访问元素,时间复杂度为O(1)
以链表访问元素,平均情况下时间复杂度为O(n)
而数组要提前预知数组的大小,创建足够大的数组,会浪费内存
而链表虽然指针变量用了额外的内存,但其碎片化的特性,在数据很大的情况下,链表占用内存更少,
例如一个数组a[7]
a[0]=2;a[1]=4;a[2]=6; a[3]=5;
数组的内存需求为7*4=28个字节
而链表的内存需求为(4+4)*4=32个字节
也就是说数据部分越大,内存的利用率越高
插入元素 在头部插入 对于数组,要将每个元素往高位移一位,花费的时间将与列表的大小成比例 ,时间复杂度为On
对于链表,在开头插入节点意味着仅创建一个新节点并调整头指针和该新节点的链接,花费时间恒定,时间复杂度为O1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 #include <stdlib.h> #include <stdio.h> struct node{ int data; struct node* next; }; struct node* head;//名为head的头指针变量,指向 尽量定义全局变量 ,定义局部会麻烦许多 void insert(int x)//创建一个node,temp存储了他的地址 { struct node* temp=(node*)malloc(sizeof(node));//malloc返回一个void型指针,因此必须强制转换 temp->data=x;//(*temp).data=x; temp->next=head; //涵盖了链表为空和不为空的情况 if(head!=NULL) temp->next=head;//若链表不为空时插入,此时的head相当于上一个temp head=temp;//从头开始插入数据 //若链表不为空时插入,即抹去之前头指针与temp的练习,head指向这个新创建的节点 }//插入数据时有两种情况,一种是链表为空,一种是链表不为空 void print() { struct node* temp=head;//使用临时变量防止修改头节点 while(temp!=NULL) { printf(" %d",temp->data); temp=temp->next;//修改临时变量的地址来遍历链表 } printf("\n"); } int main() { head=NULL ;//链表为空 int n; scanf("%d",&n); int i; int x; for(i=0;i<n;i++) { scanf("%d",&x); insert(x); print();//打印 } }
在尾部插入 若数组未满,则为O1,若已满,则又将花费On的时间,
对于链表,将遍历链表,并调整尾指针的指向,On
在第i个位置插入 数组和链表同样是On
并且将i-1个节点的连接设置为此新创建的节点的地址
全局变量,栈,堆
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 #include <stdio.h> #include <stdlib.h> struct node{ int date; struct node* link; }; struct node* head; void insert(int date,int n) { struct node* temp1=(struct node*)malloc(sizeof(struct node*));//node* temp1=new node(); temp1->date=date; temp1->link=NULL; if(n==1)//不管现有的头部是什么,调整此变量以指向新的头部 { temp1->link=head; head=temp1; return ; } struct node* temp2=head; for(int i=0;i<n-2;i++)//此时已经指向第一个节点,经过n-2次循环指向n-1个节点 { temp2=temp2->link;//到达第n-1个节点 } temp1->link=temp2->link;//temp2是我们到达n-1节点的一个工具, temp2->link=temp1; } void print() { struct node* temp=head; while(temp!=NULL) { printf("%d ",temp->date); temp=temp->link; } printf("\n"); } int main() { head=NULL; insert(2,1); insert(3,2); insert(4,1); insert(5,2); print(); return 0; }
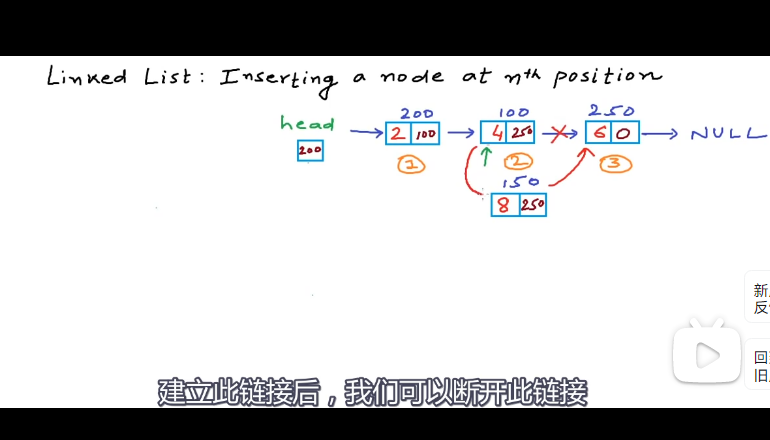
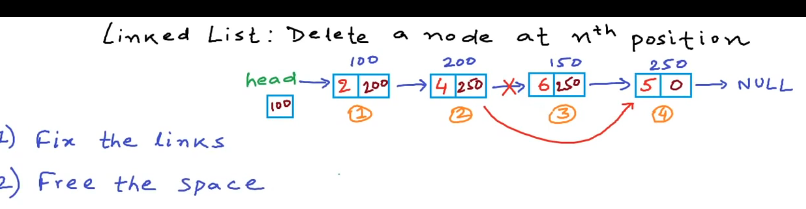
在任意位置删除节点 对于删除第n个节点,我们不得不到n-1个节点,我们必须将第n-1个节点的链接部分设置为第n个节点,也就是第n+1个节点
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 #include <stdio.h> #include <stdlib.h> struct node{ int data; struct node* link; }; struct node* head; void insert(int data)//在末尾插入数据 { struct node* temp1=(struct node*)malloc(sizeof(struct node*));//node* temp1=new node(); temp1->data=data; temp1->link=NULL; if(head==NULL) { temp1->link=head; head=temp1; return ; } struct node* temp2=head; while(temp2->link!=NULL) { temp2=temp2->link; } temp2->link=temp1; temp1->link=NULL; } void print() { struct node* temp=head;//使用临时变量防止修改头节点 while(temp!=NULL) { printf(" %d",temp->data); temp=temp->link;//修改临时变量的地址来遍历链表 } printf("\n"); } void del(int n)//删除第n个节点 { struct node* temp1 =head; if(n==1) { head=temp1->link; free(temp1); return ; } int i; for(i=0;i<n-2;i++) { temp1=temp1->link; } struct node* temp2=temp1->link;//类似于swag,temp2是一个工具 ,暂时存放link temp1->link=temp2->link; free(temp2);//delete temp2 } int main() { head=NULL; insert(2); insert(4); insert(6); insert(5);// 2 4 6 5 int n; scanf("%d",&n); del(n); print(); }
反转链表 head为全局变量版本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 #include <stdio.h> #include <stdlib.h> struct node{ int data; struct node* link; }; struct node* head; void insert(int data,int n) { struct node* temp1=(struct node*)malloc(sizeof(struct node*)); temp1->link=NULL; temp1->data=data; if(n==1) { temp1->link=head; head=temp1; return ; } struct node* temp2=head; for(int i=0;i<n-2;i++) { temp2=temp2->link; } temp1->link=temp2->link; temp2->link=temp1; } void print() { struct node* temp=head; while(temp!=NULL) { printf("%d ",temp->data); temp=temp->link; } printf("\n"); } void re() { struct node *current,*prev,*next; current=head; prev=NULL; while(current!=NULL) { next=current->link;//为了到达下一个节点 current->link=prev; prev=current; current=next; } head=prev; } int main() { head=NULL; insert(2,1); insert(3,2); insert(4,1); insert(5,2); print(); re(); print(); }
局部变量head版本,因为项目当中尽量避免全局变量
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 #include <stdio.h> #include <stdlib.h> struct node{ int data; struct node* link; }; struct node* re(struct node* head) { struct node *current,*prev,*next; current=head; prev=NULL; while(current!=NULL) { next=current->link; current->link=prev; prev=current;; current=next; } head=prev; return head; } struct node* insert(node* head,int data) { node *temp=(struct node*)malloc(sizeof(struct node)); temp->data=data; temp->link=NULL; if(head==NULL) head=temp; else { node* temp1=head; while(temp1->link!=NULL) temp1=temp1->link; temp1->link=temp; } return head; } void print(struct node* p) { if(p==NULL) { return ; } printf("%d ",p->data); print(p->link); } int main() { struct node* head=NULL; head=insert(head,2); head=insert(head,4); head=insert(head,6); head=insert(head,8); print(head); head=re(head); printf("\n"); print(head); }
反转链表 递归 隐式的使用了栈
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 #include <stdio.h> #include <stdlib.h> struct node{ int data; struct node* link; }; struct node* head; void re(struct node* p) { if(p->link==NULL)//注意双等于 { head=p; return ; } re(p->link);//这里的p->next=NULL只有第一个迭代是必须的,之后的迭代都会被q->next=p重置,之所以每次都清理是因为除非定义一个另外的变量,否则无法知道什么时候回到第一次递归 struct node* q=p->link; q->link=p; p->link=NULL; } void insert(int data,int n) { struct node* temp1=(struct node*)malloc(sizeof(struct node*)); temp1->data=data; temp1->link=NULL; if(n==1) { temp1->link=head; head=temp1; return ; } struct node* temp2=head; for(int i=0;i<n-2;i++) { temp2=temp2->link; } temp1->link=temp2->link; temp2->link=temp1; } print() { struct node* temp=head; while(temp!=NULL) { printf("%d ",temp->data); temp=temp->link; } printf("\n"); } void gg() { printf("\n"); } int main() { head=NULL; insert(2,1); insert(4,2); insert(6,3); print(); gg(); re(head); print(); }
代码实现中c与c++的区别 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 #inc lude <iostream> using namespace std; struct node{ int date;//整形链表 struct node* link; };//c语言 struct node{ int date; node* link; };//c++ //以下用c++实现,较方便,不同点同上 int main() { //起初没有元素 node* a;//a指针用于指向头节点 a=NULL; //不指向任何具体节点,因此列表为空 node* temp=(node*)malloc(sizeof(node)); (*temp).date=2;//temp指向的值的地址 a=temp; //////////////////c++ node* a; a=NULL; node* temp=new node();// 创建几个节点的声明,之后调用直接用 temp temp->date=2; temp->link=NULL; a=temp; temp=new node(); temp->date=4; temp->link=NULL node* temp1=a;//遍历链表 注意此处仅是借用了a,并没有修改,头节点不可修改,修改会丢失头节点地址 a没有link while(temp1->link !=NULL) { temp1=temp1->link; } temp1->link=temp; node* temp1=a;//遍历链表并输出 while(temp1->link !=NULL) { temp1=temp1->link; cout<<temp1->date; } }
递归打印列表 递归会让函数叠在栈里, 打印的时候, 出栈的返回值会倒叙送给print函数去打印
递归学的有些烂,学完数据结构得去学学算法了😨
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 #include <stdio.h> #include <stdlib.h> struct node{ int data; struct node* link; }; struct node* insert(node* head,int data) { node *temp=(struct node*)malloc(sizeof(struct node)); temp->data=data; temp->link=NULL; if(head==NULL) head=temp; else { node* temp1=head; while(temp1->link!=NULL) temp1=temp1->link; temp1->link=temp; } return head; } void print(struct node* p) { if(p==NULL) { return ; } printf("%d ",p->data); print(p->link); } void printre(struct node* p) { if(p==NULL) return ;//我的理解是递归结束,无视第二行,进行一个栈中的打印 printre(p->link); printf("%d ",p->data); } int main() { struct node* head=NULL; head=insert(head,2); head=insert(head,4); head=insert(head,6); head=insert(head,5); printre(head); }
双向链表 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 #include <stdio.h> #include <stdlib.h> struct node{ int data; struct node* link; struct node* prev; }; struct node* head; struct node* get(int x) { struct node* newnode=(struct node*)malloc(sizeof(struct node)); newnode->data=x;//我们无法在栈上控制的内存和释放,所以通过malloc开内存,在堆上使用内存 newnode->link=NULL;//访问堆的唯一方式就是通过指针,如果我们失去该指针,我们将失去该节点 newnode->prev=NULL; return newnode; } void inserthead(int x) { struct node* temp=get(x); if(head==NULL) { head=temp; return; } head->prev=temp; temp->link=head; head=temp; } void print(){ struct node* temp=head; printf("Forward "); while(temp!=NULL) { printf("%d ",temp->data); temp=temp->link; } printf("\n"); } void reprint(){ struct node* temp=head; if(temp==NULL) { return ; } while(temp->link!=NULL) { temp=temp->link; } printf("Reserve "); while(temp!=NULL) { printf("%d ",temp->data); temp=temp->prev; } printf("\n"); } int main() { head=NULL; inserthead(2); print(); reprint(); inserthead(4); print(); reprint(); inserthead(6); print(); reprint(); }
单调栈和单调队列 树 二叉树 二叉树判定的唯一条件是一个节点不能有超过两个孩子
除最深的一层外补满,且最后一层二叉树左对齐,称为完全二叉树,若所有都填满,称为完美二叉树
树中操作的复杂度正比于树的高度
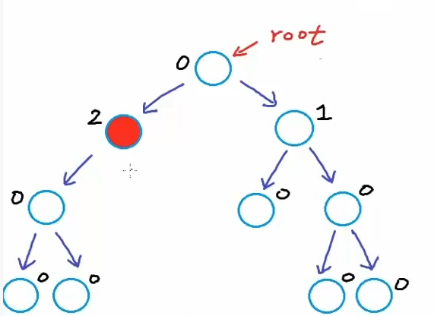
平衡二叉树:每一个节点的左子树和右子树的高度差小于等于1
例如:如图的树便不是平衡二叉树
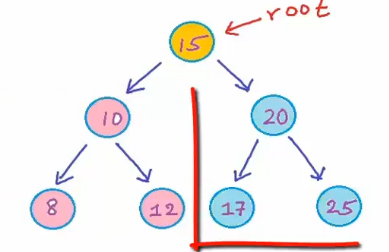
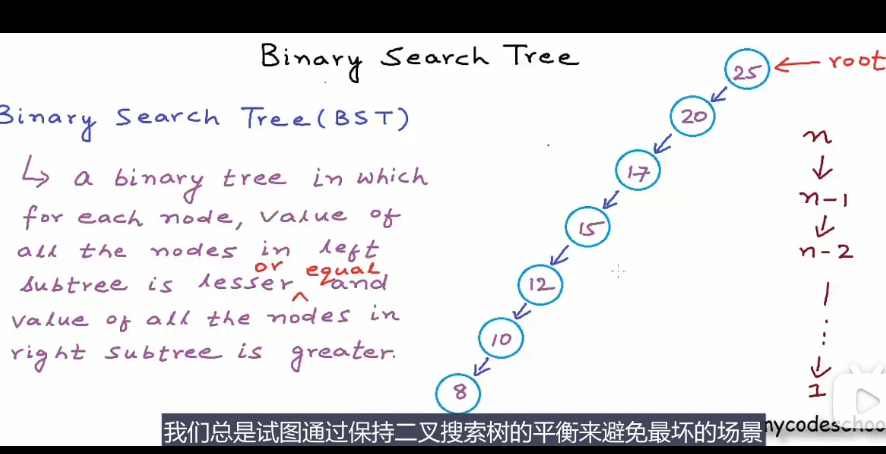
二叉搜索树 存储集合的数据结构
可以查询插入删除集合中的元素
保证树是平衡的可以避免最坏情况
二叉搜索树是一种二叉树,其中的而每一个节点,所有左子树上的节点值都比该节点的要小,所有右子树上的节点值都比该节点的值要大
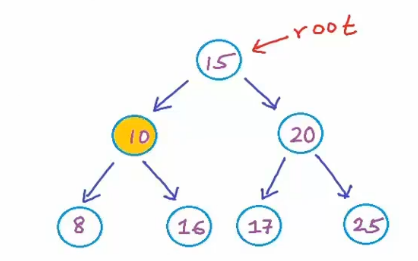
第二张就不是了
但最好还是完美二叉树
二叉搜索树c++实现