逆向基础知识以及部分加解密算法
学习逆向实际上是学习如何破解“阻碍逆向的方法”
病毒
自有协议
非公开
用加密阻碍逆向
C
重载运算符
寄存器
X86寄存器
| 通用寄存器 | EAX | RBX | ECX | EDX | ESI | EDI |
|---|---|---|---|---|---|---|
| 栈顶指针寄存器 | ESP | |||||
| 栈底指针寄存器 | EBP | |||||
| 指令计数器 | EIP | |||||
| 段寄存器 | CS | DS | SS | ES | FS | GS |
X86-64寄存器
| 通用寄存器 | RAX | RBX | RCX | RDX | RSI | RDI |
|---|---|---|---|---|---|---|
| 栈顶指针寄存器 | RSP | |||||
| 栈底指针寄存器 | RBP | |||||
| 指令计数器 | RIP | |||||
| 段寄存器 | CS | DS | SS | RS | FS | GS |
16寄存器
| 通用寄存器 | AX | BX | CX | DX | SI | DI |
|---|---|---|---|---|---|---|
| 栈顶指针寄存器 | SP | |||||
| 栈底指针寄存器 | BP | |||||
| 指令计数器 | IP | |||||
| 段寄存器 | CS | DS | SS | S | FS | GS |
常见加密算法识别
刷题中遇见一点写一点
RC4加密算法
属于流加密算法,包括初始化函数和加解密函数
可以容易的发现两个256循环,第一个循环给s盒赋值,第二个循环根据密钥key对S盒进行swap。根据源码的了解,a2中保存的是密钥key
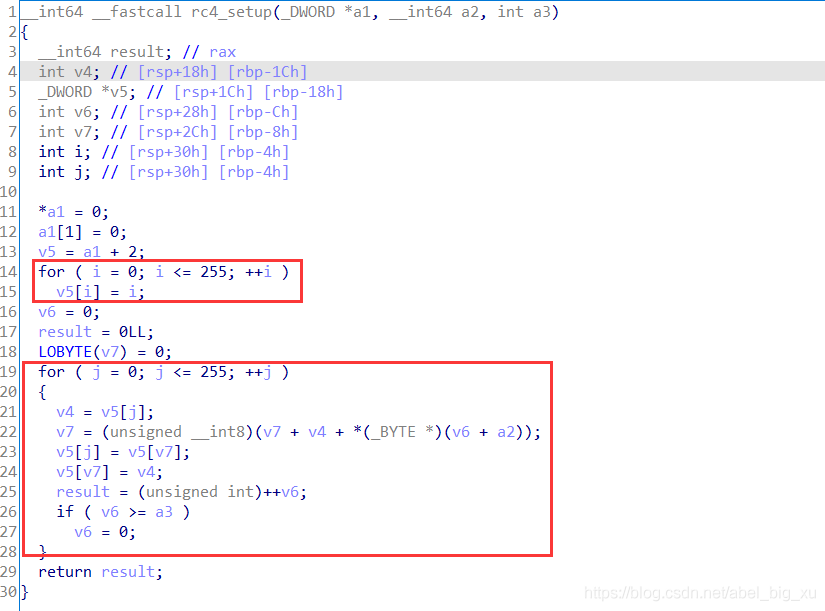
循环中最关键的就是S盒的swap,明文和S盒的异或。其中v6为S盒,a2指向明文和密文。
虽然工具无法直接识别出RC4算法,但是RC4算法比较简单,主要的3个for循环,前两个256循环为S盒初始化,最后一个循环异或生成密文。可以通过调试初始化代码找到每次RC4的密钥key。
例题:ctfshow的re2
我真没想到第二题就搞这种的,真不会做。。。
发现关键函数sub_401A70:
1 | char __cdecl sub_401A70(char *Str, char *Str1) |
0x1F 转十六进制为31
写脚本
1 | str='DH~mqqvqxB^||zll@Jq~jkwpmvez{' |
发现不是flag,然后在IDA中发现了另一个函数sub_4015E0:
1 | __CheckForDebuggerJustMyCode(&unk_40B027); |
百度上偷来的代码
1 | //程序开始 |
rc4编码应该不用改代码,让我改我也不会😎
在main函数的地方做适当修改:
1 | int main() |
得到flag
1 | pData=flag{RC4&->ENc0d3F1le} |
Base64解密
南邮CTF py交易
反编译pyc发现
encode函数,将输入的每一个字符异或32,每一个字符ascii加16,再以base64加密
所以我们只需将”XlNkVmtUI1MgXWBZXCFeKY+AaXNt”进行base64解密,再将每个字符ascii码都减16,接着与32异或即可得
到flag
1 | import base64 |
汇编语言
计算机的组成
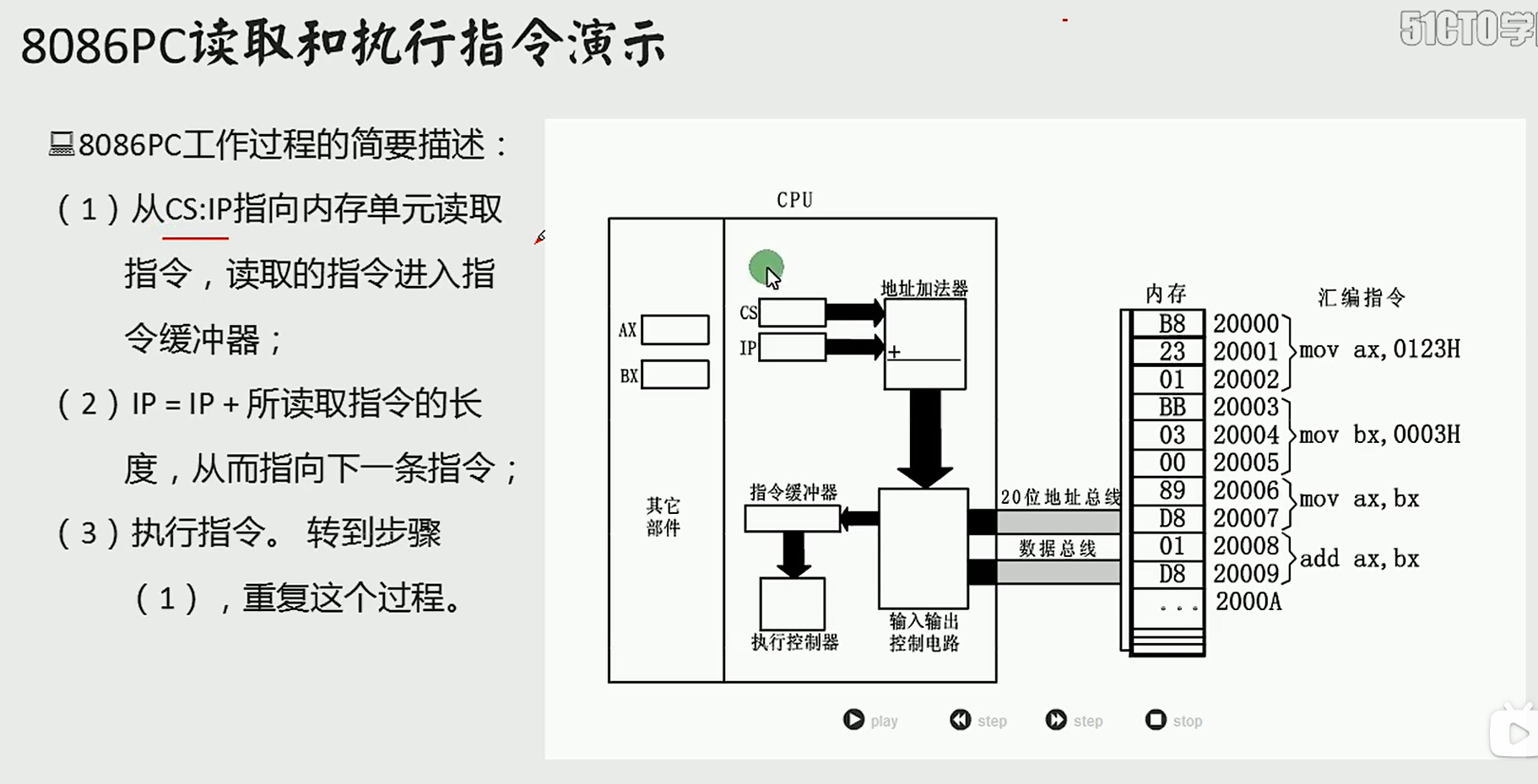
CPU是计算机的核心部件,它控制整个计算机的运作并进行运算,要想让一个CPU工作,就必须向它提供指令和数据。
指令和数据在存储器(内存)中存放。离开了内存,再好的CPU都无法工作
指令和数据的表示

为了便于记忆
二进制Best
十六进制 Huge
八进制 O?
十进制 Daily
每四个十六进制数对应一个二进制数
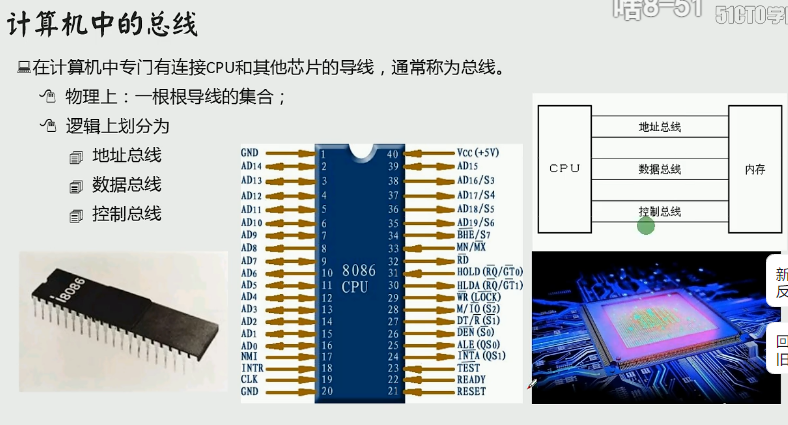
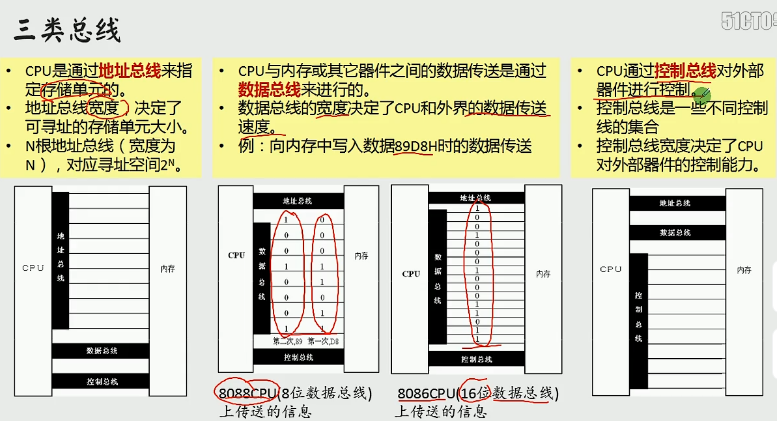
因为每一根线都可以传输数据0或1,这两个数,n根就是二的N次方
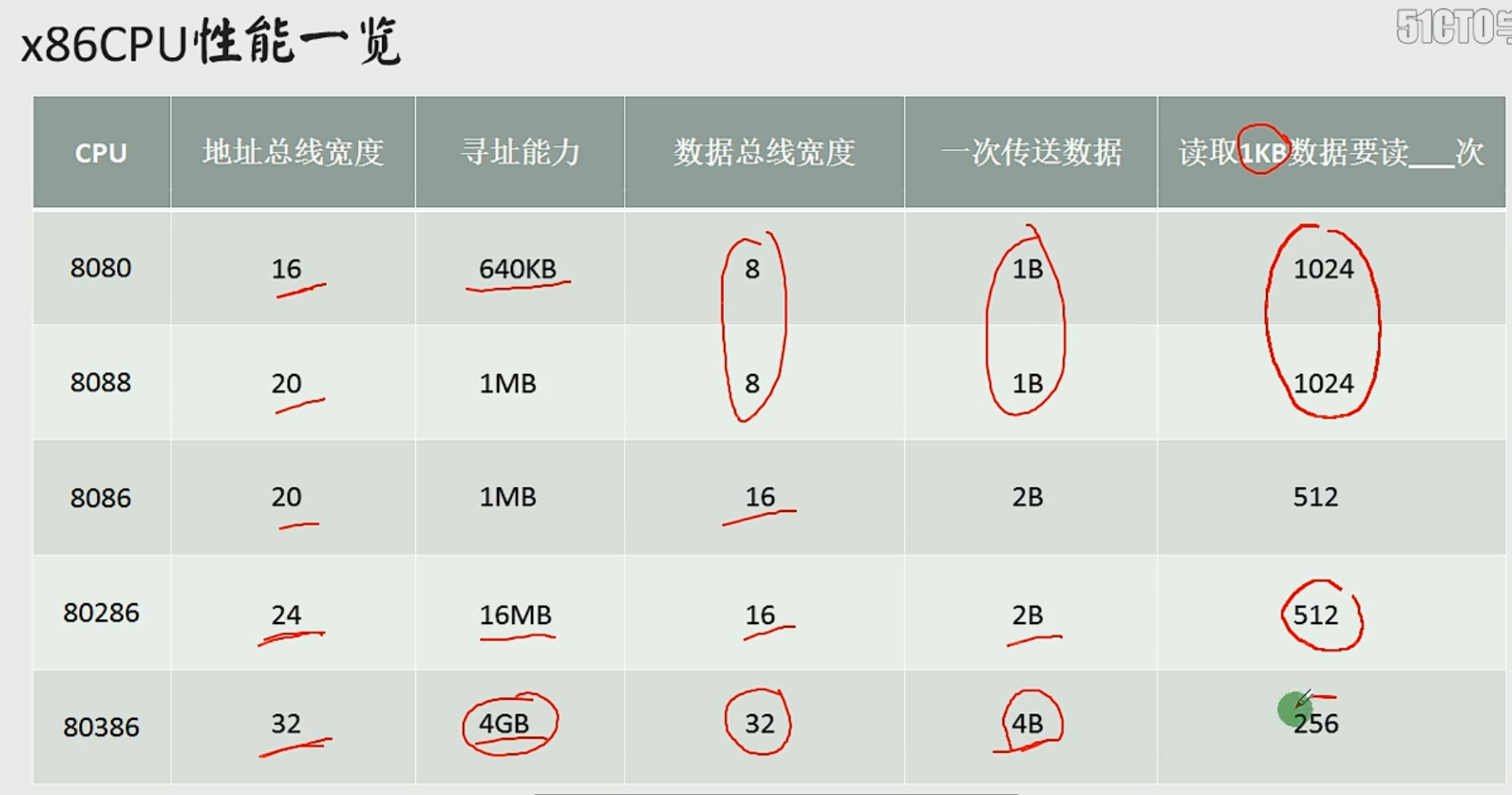
内存的读写与地址空间

地址 选择 数据

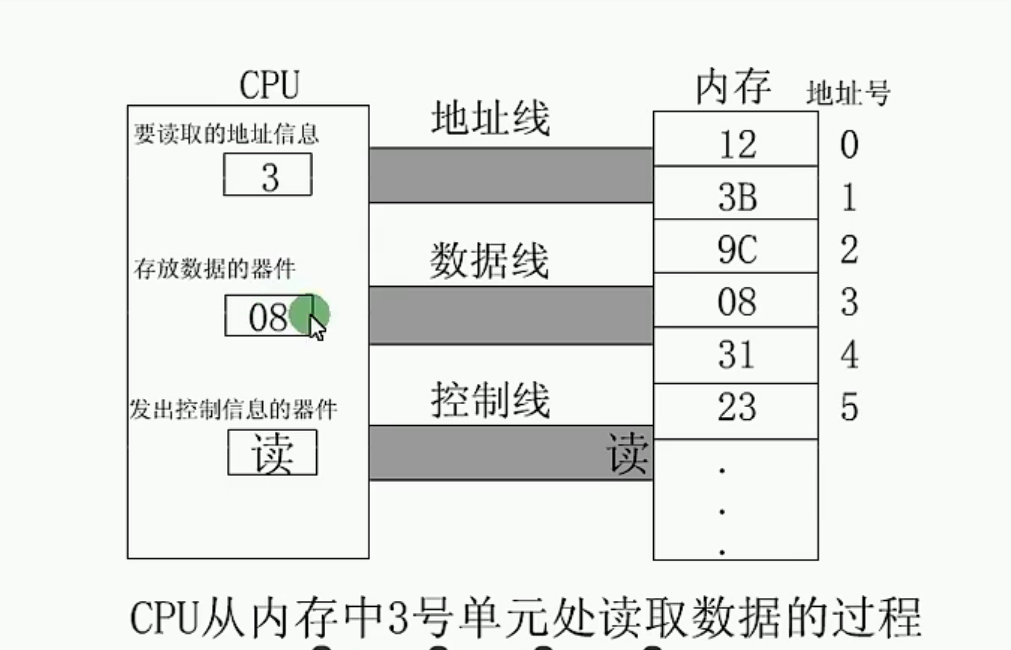
由读取的地址信息3从地址线传到内存当中,找到3号单元,此时控制线发出读的信号,3号单元的08就通过数据线传到了al寄存器
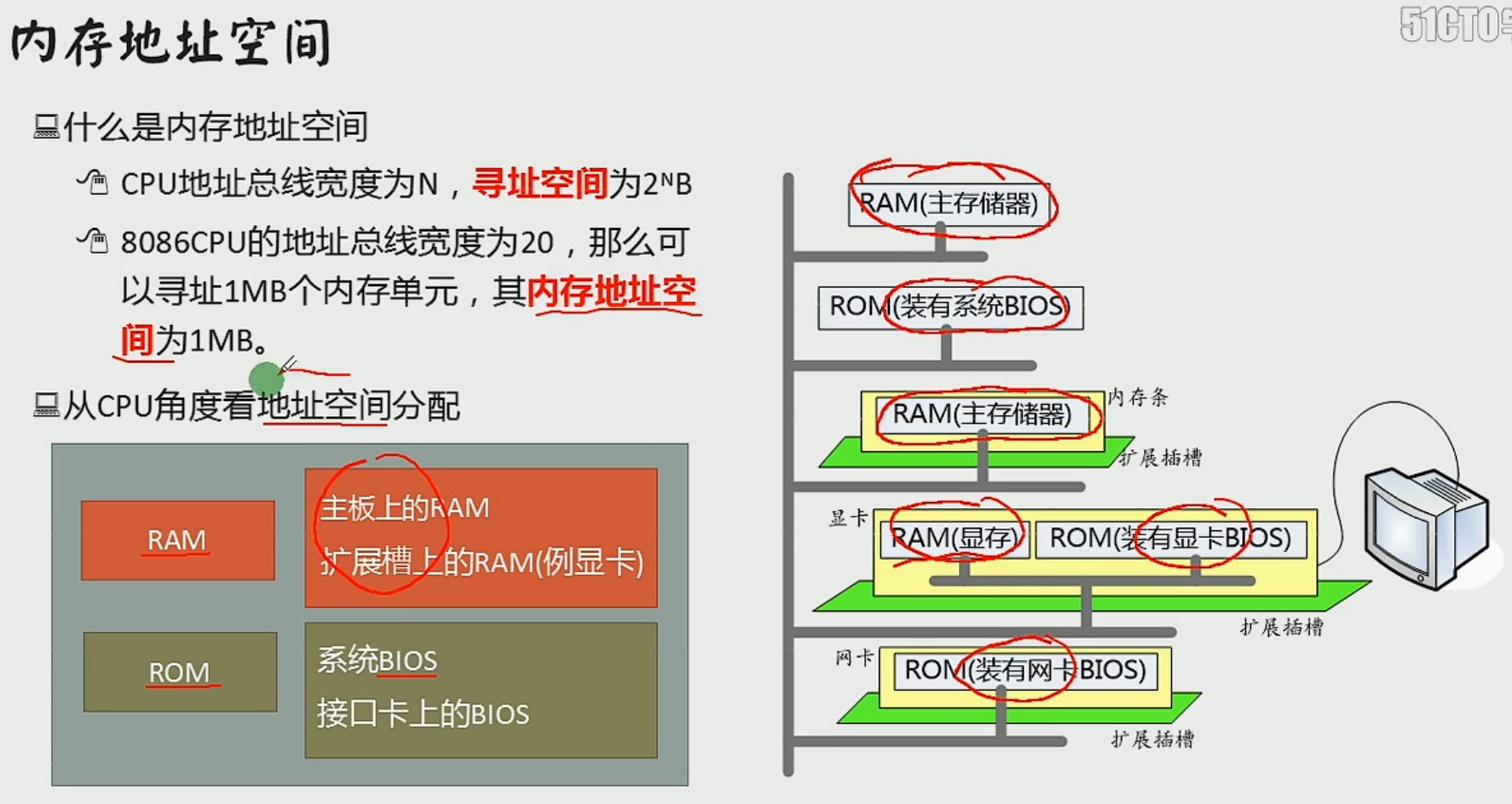
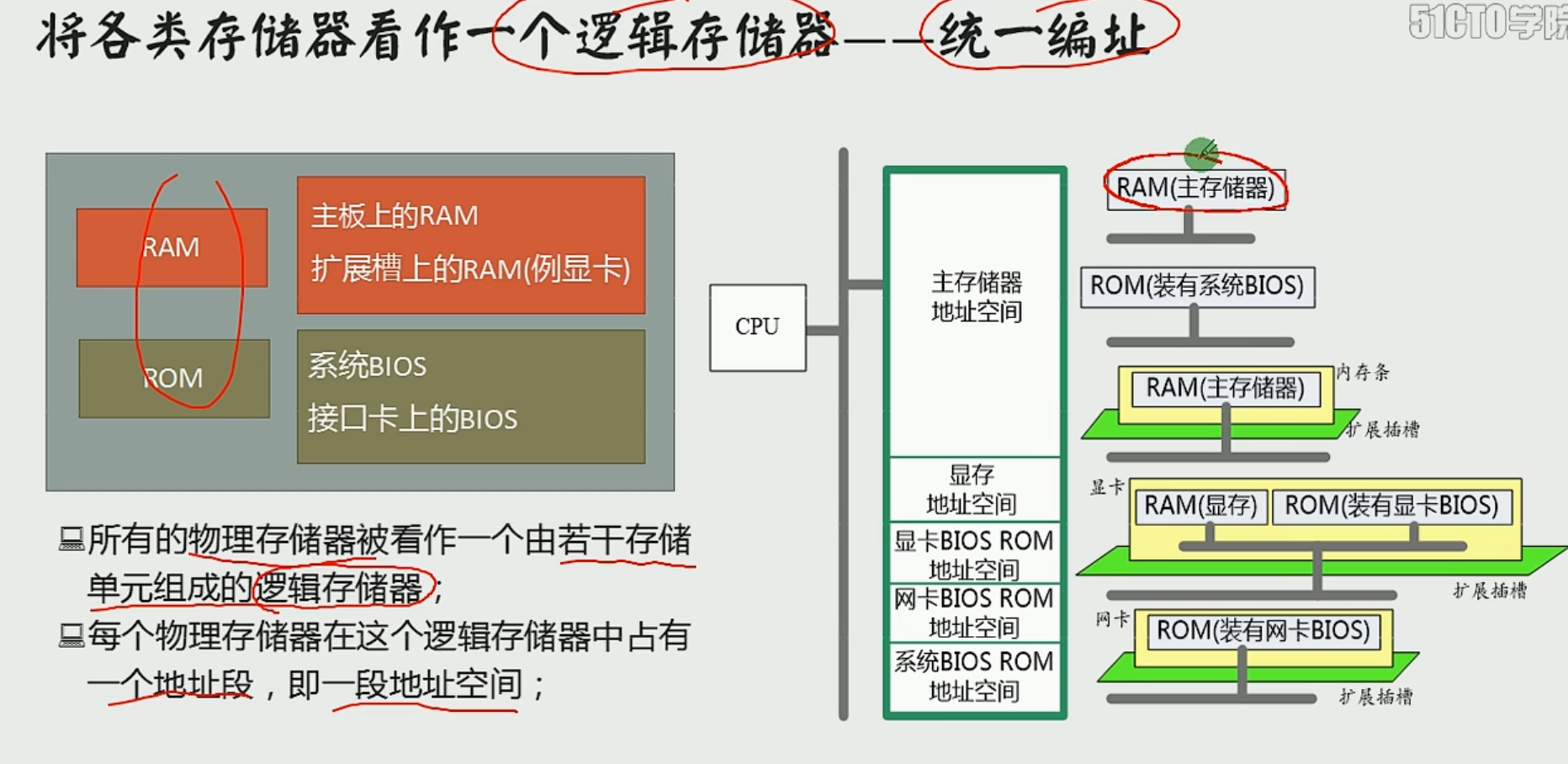
看为整体,并分配地址
就像一个公司(逻辑存储器),有不同部门(物理存储器),不同部门有不同的办公区域(地址段或),部门有很多人(存储单元)
在地址空间中读写数据,实际上就是在相对应的物理存储器中读写数据
8086的分配方案
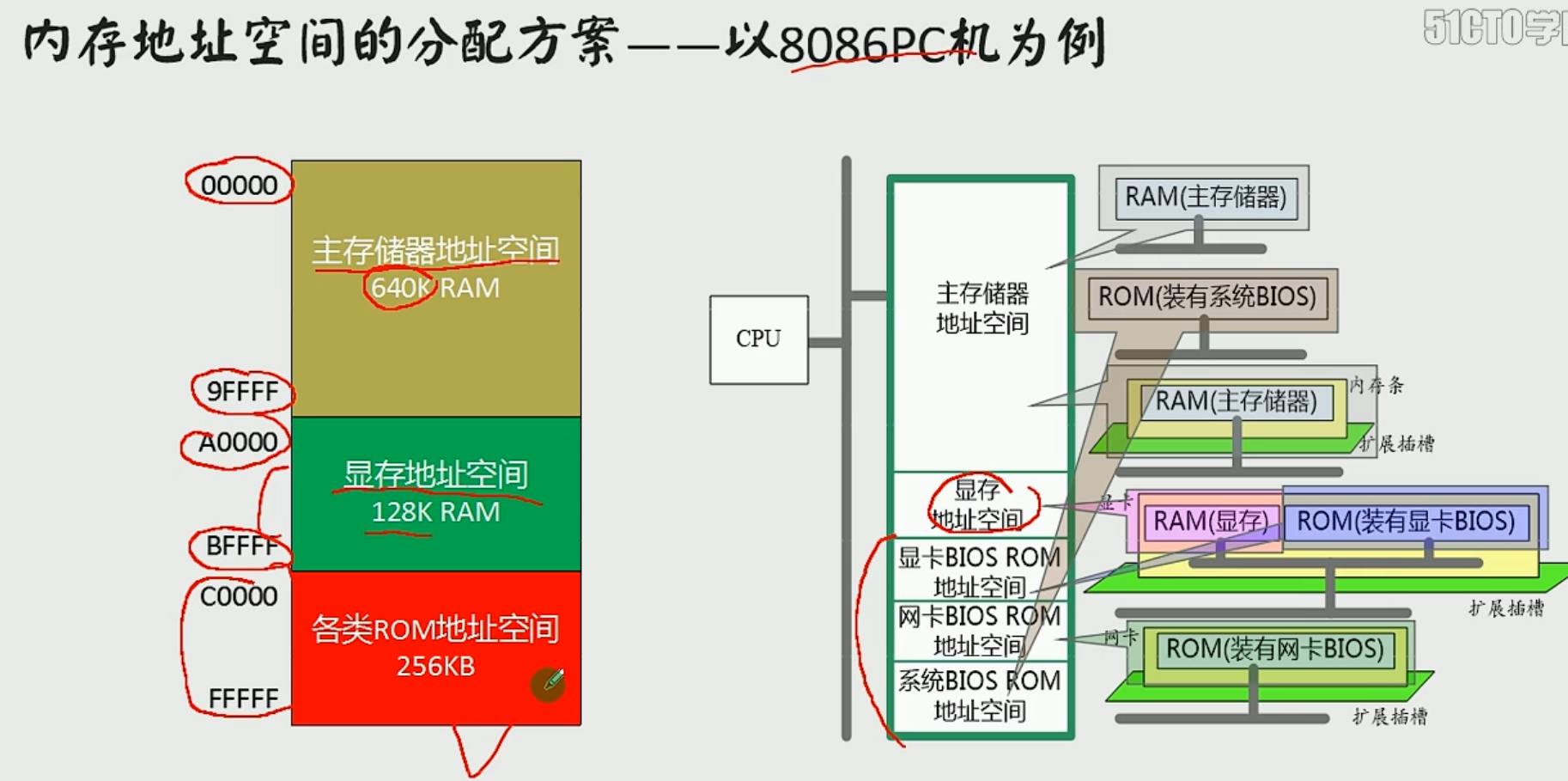
在编写汇编语言程序前,需先确定其型号

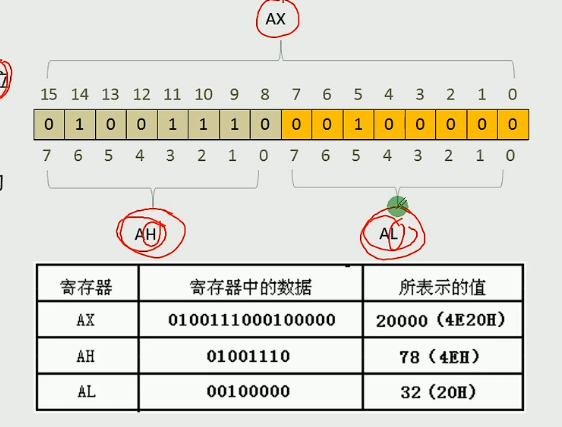
寄存器及其存储数据
问题:8086上一代CPU的寄存器都是八位如何保证程序的兼容性
方案:通用寄存器均可以分为两个独立的8位寄存器使用
细化:AX寄存器可以分为AH和AL
H:high
L:low


add 两数据相加,结果存在前面的寄存器中
mov 将右面的数据送入左边的寄存器
汇编指令不区分大小写
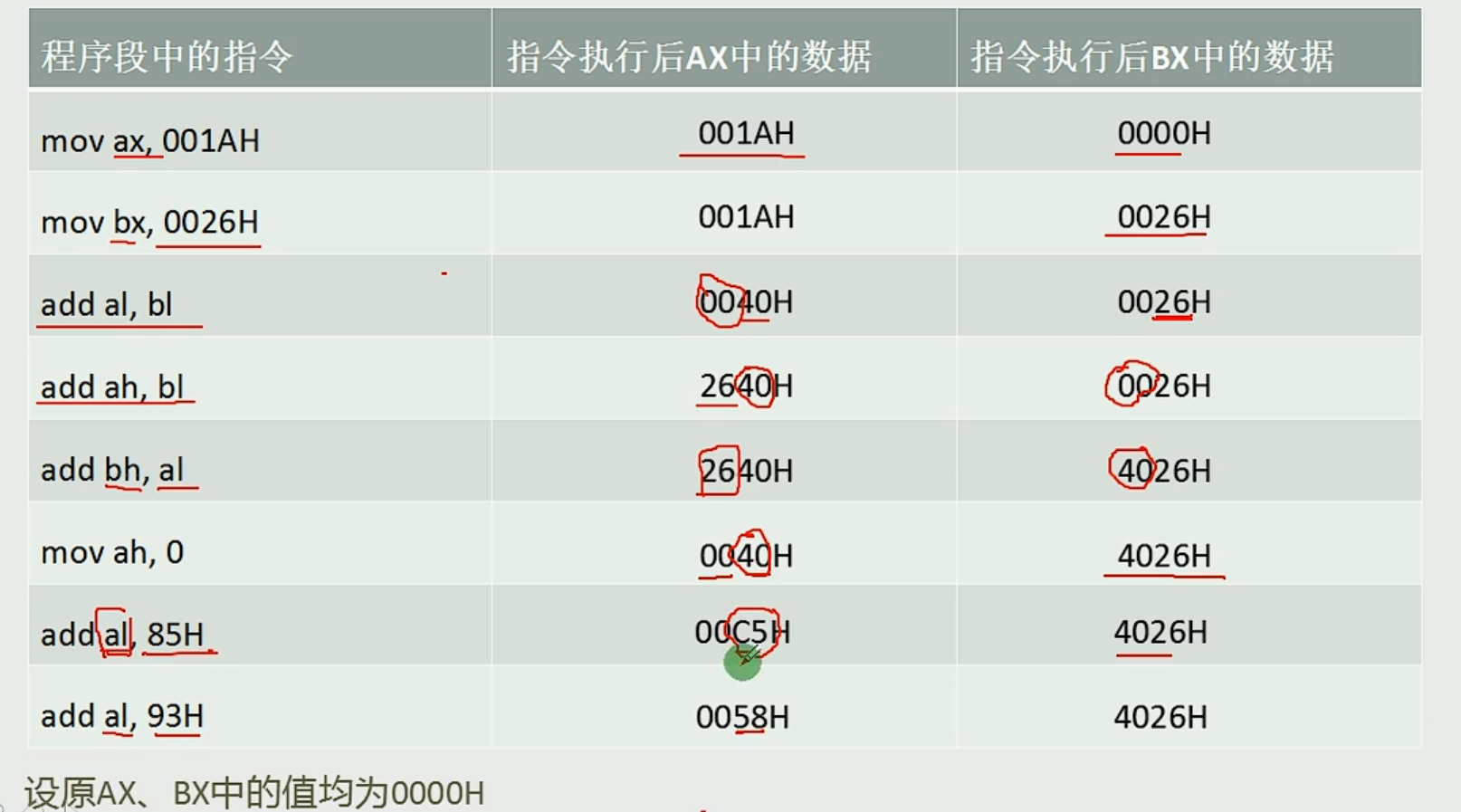
0058H低位的计算结果为158,1溢出
一个数乘以二就等于自己加它自己
确定物理地址的方法

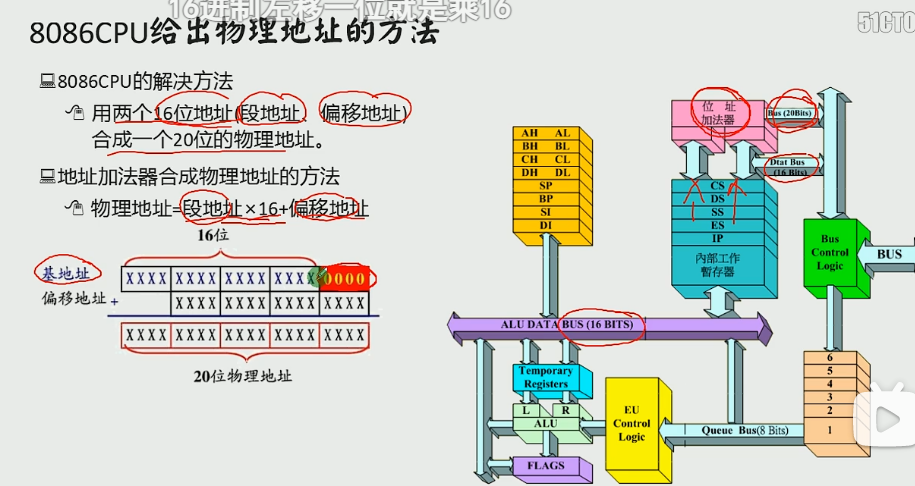
二进制左移一位就是乘二
左移四位就是乘十六
十六进制左移一位就是乘十六

段地址只是为了表示物理地址的工具

基础地址和一个相对于基础地质的偏移地址相加
内存的分段表示法
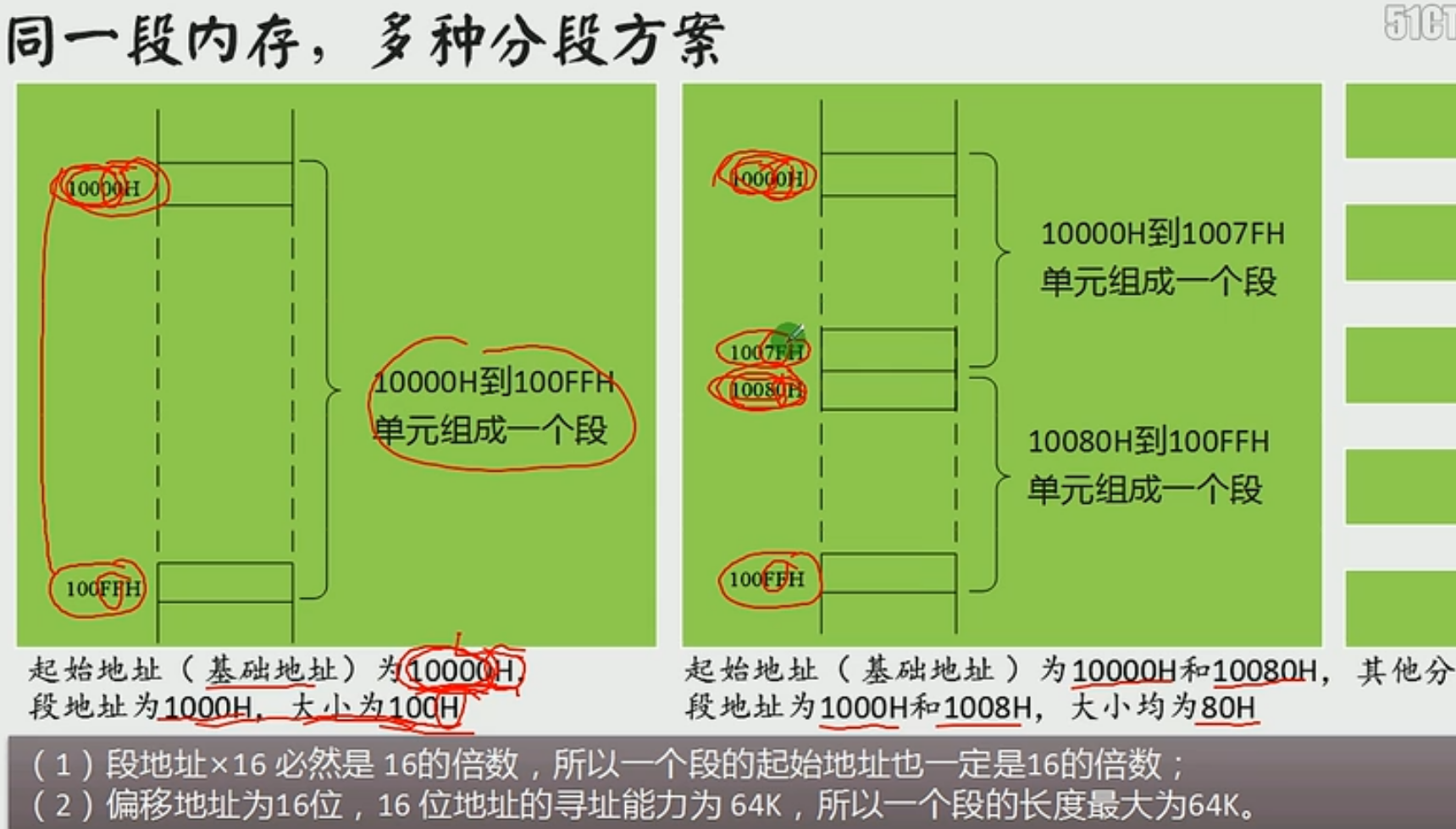
内存是一个整体,分段是CPU分的
偏移地址为16位,16位地址的寻址能力是64k,所以一个段的最大长度是64k

数据在21F60内存单元中,段地址是2000H,说法:
数据存在内存2000:1F60单元中
数据存在内存的2000H段中的1F60单元中

CS c code s segment 分段
DS d data 数据
SS s stack 栈
ES Extra 额外的附加的
Debug的使用
先挂载
1 | mount c e:\masm |
dos中使用的c盘实际上是e:\masm
每一次进都要输
进入目录
1 | c: |
列出目录:
1 | dir |

R

D
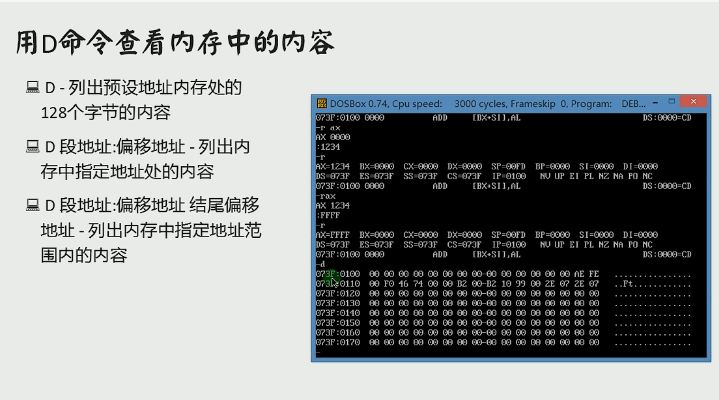

也可以指定查看需要的内容
E
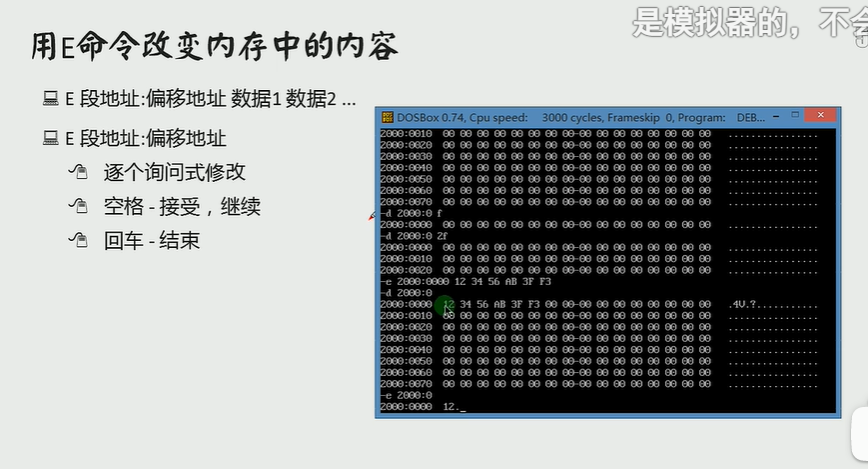
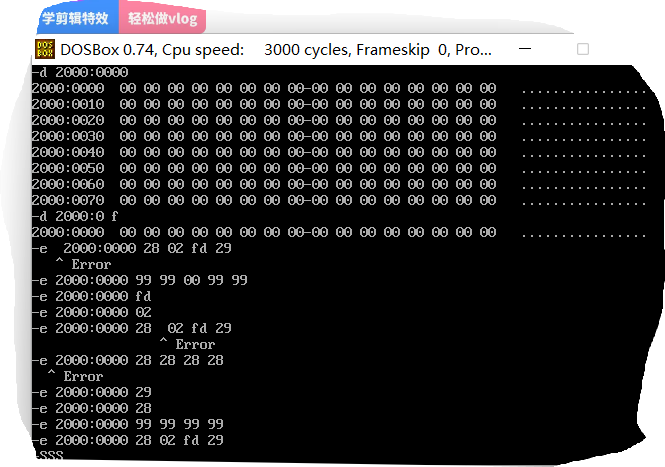
每一次会弹出当前的值,并让你输入要修改的值,空格确定并继续,回车结束操作
这截图笑死我
报错了几次,是多打了空格的原因
U
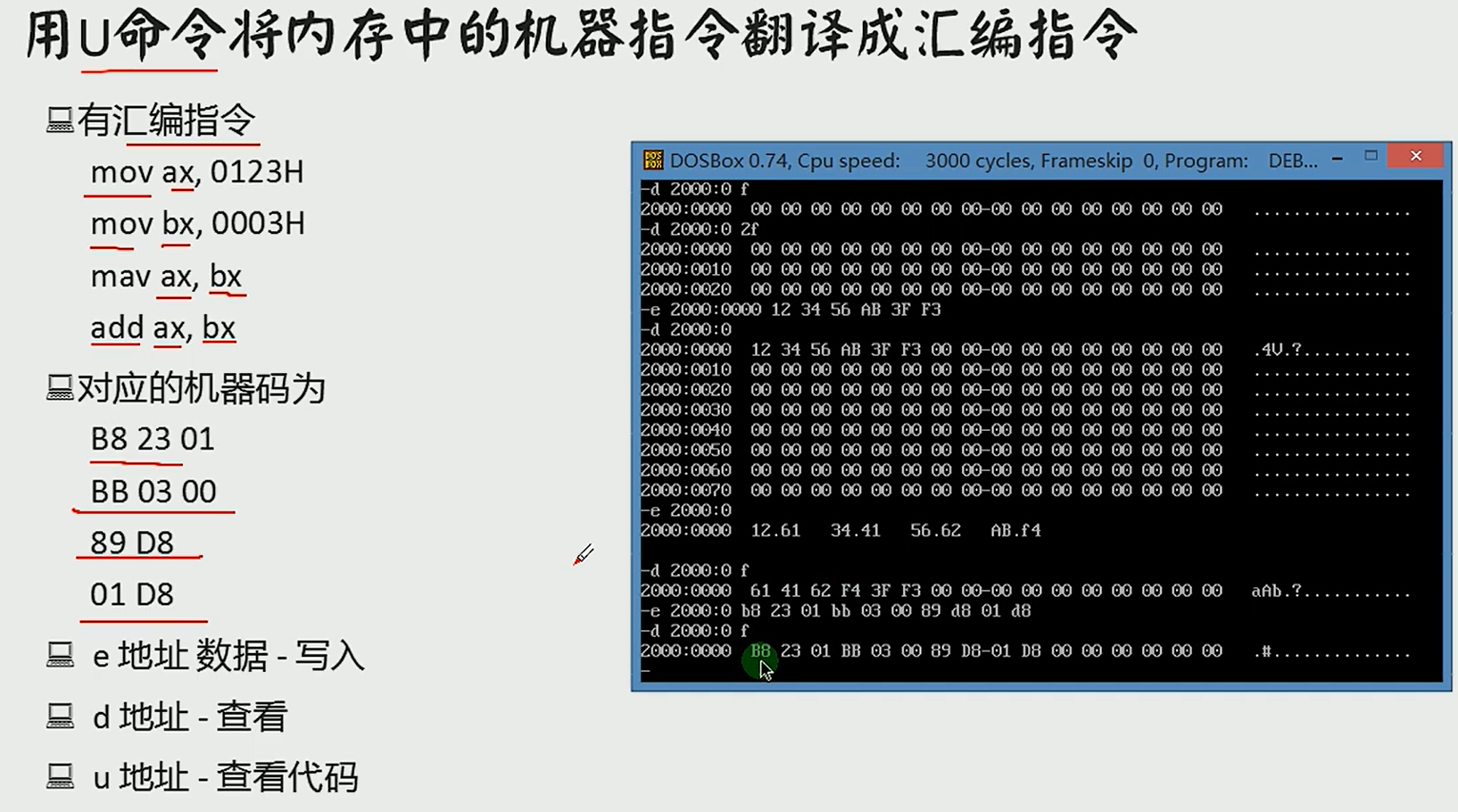
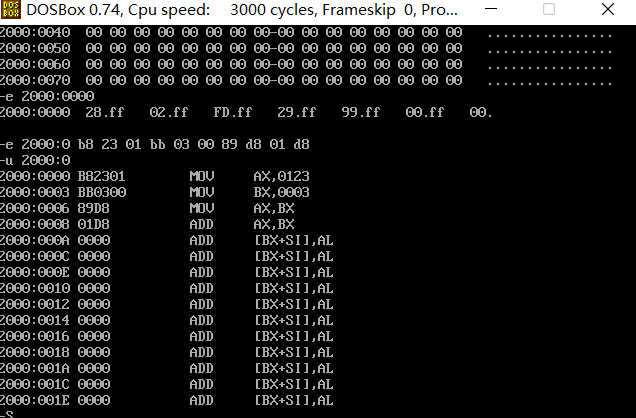
A

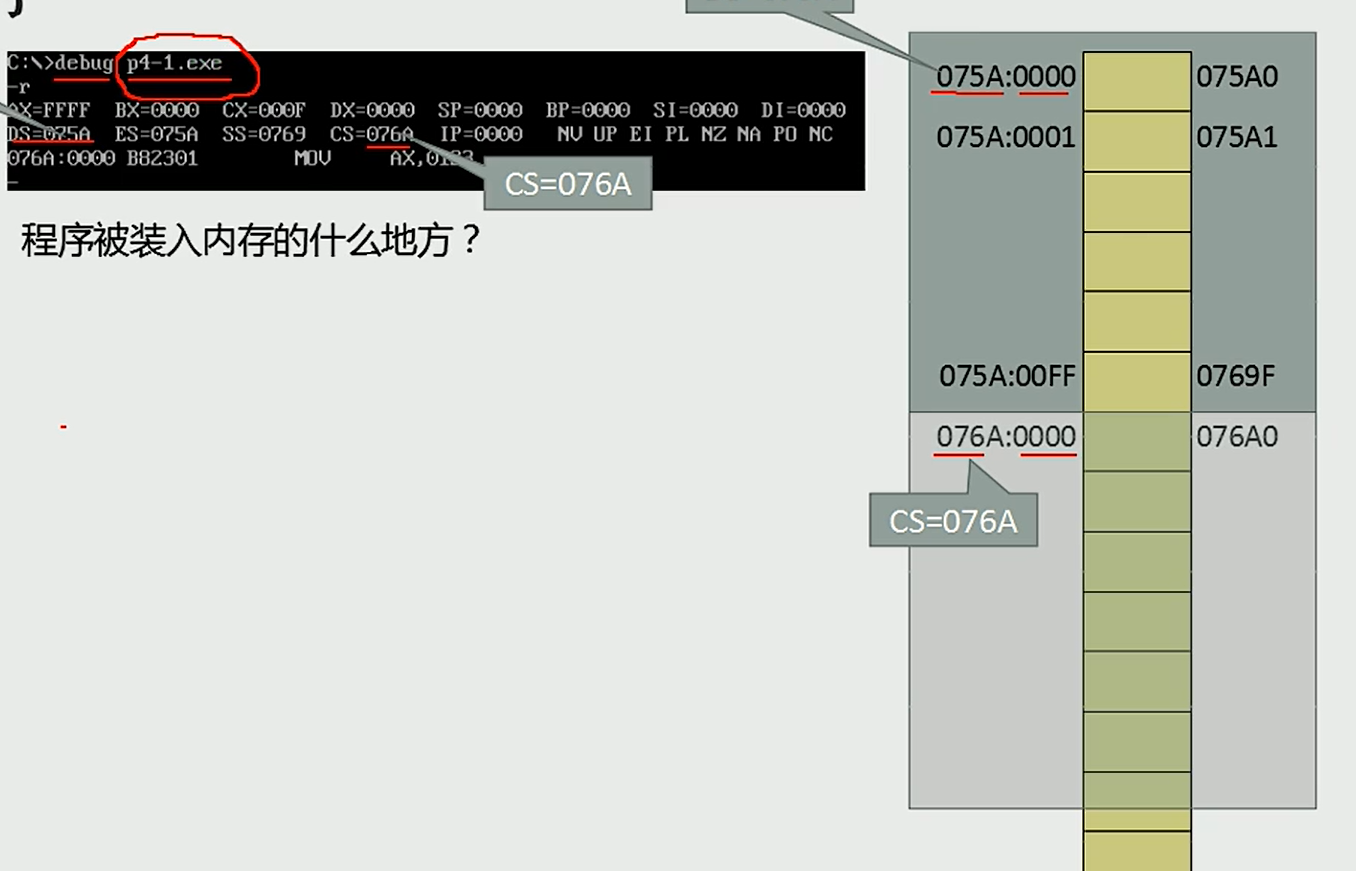
- CS是代码段寄存器,IP为指令指针寄存器,他们一起合作指向了CPU当前要读取的指令地址,可以理解为CS和IP结合,组成了PC寄存器。
- 任何时刻,8086CPU都会将CS:IP指向的指令作为下一条需要取出的执行指令。
- 8086CPU中的计算公式为 (CS << 4)|IP, 即CS左移4位,然后再加上IP。
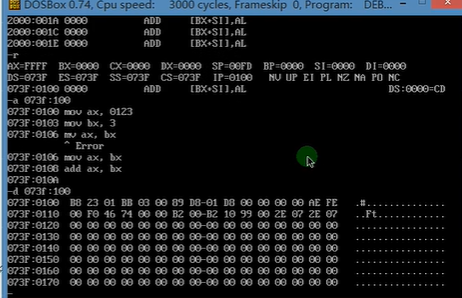
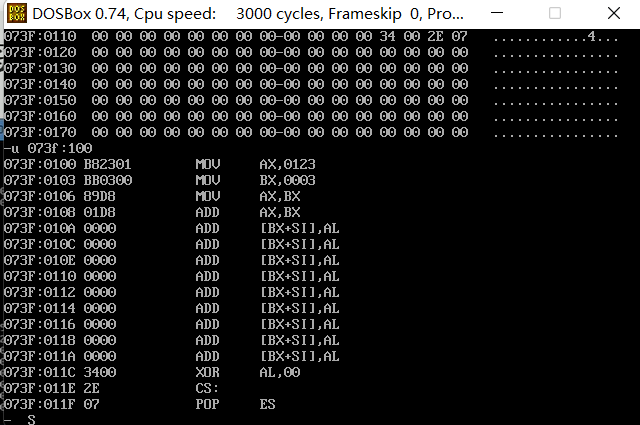
T

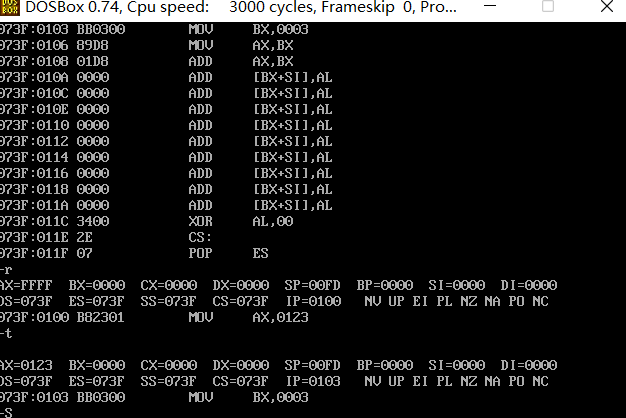
每执行一条命令ip寄存器就偏移一次
cs ip
cs:代码段寄存器
ip:指令指针寄存器
cs:ip:cpu内容将内存中的cs:ip指定的内容当作指令执行

jmp指令
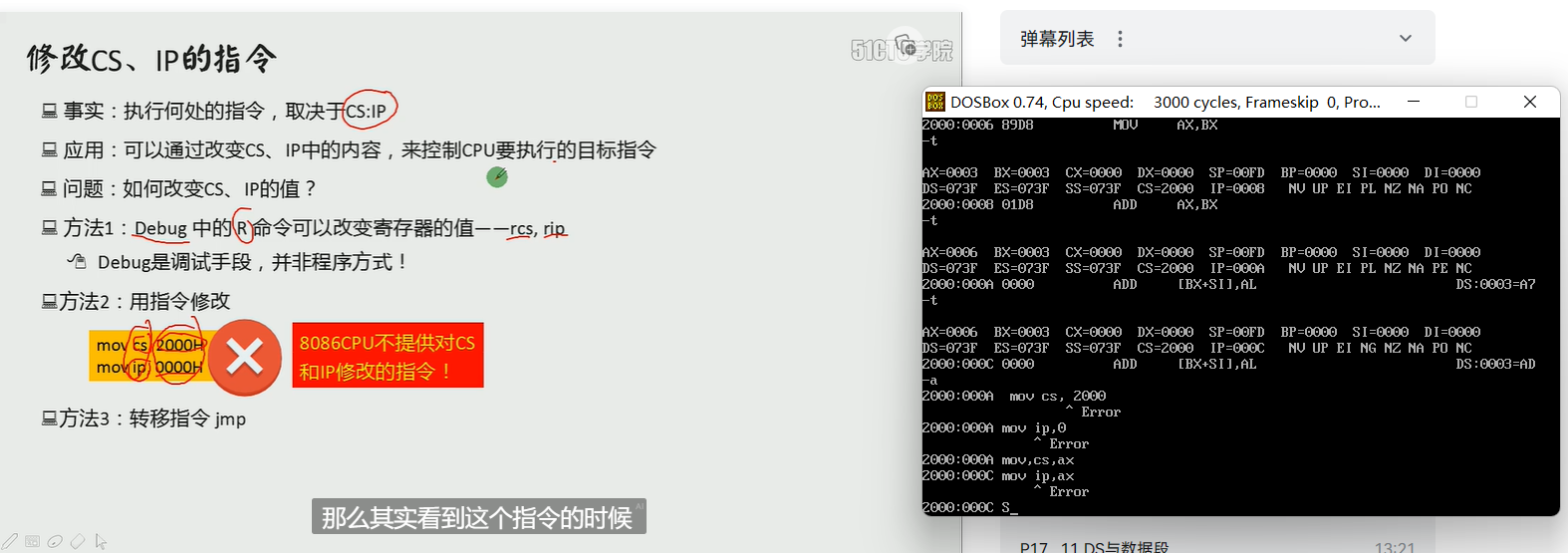
jmp可以同时修改cs,ip的内容
jmp 段地址:偏移地址
用指令中给出的段地址修改cs,偏移地址修改ip
也可以仅仅修改ip的内容
jmp 某一合法寄存器
jmp ax 类似于 mov ip,ax
jmp bx
默认是按指令物理顺序执行,可以通过跳转改变下一条要执行指令的地址
实验2: 将下面的3条指令写入从2000:0开始的内存单元中,利用3条指令计算2的8次方
mov ax,1
add ax,ax
jmp 2000:0003
第一步将1放入ax寄存器(2000:0)
第二步将ax寄存器的内容乘以二(2000:3)
第三步,将CS:IP指令指向第二步的位置
此时应该比较明确了,我们每按t执行一次都会得到2的n次方
并且第三步跳到2000:3使得我们下一次执行还是让ax=ax+ax
而jmp 2000:0003起到了循环的效果
所以我们按8次就得到2^8了
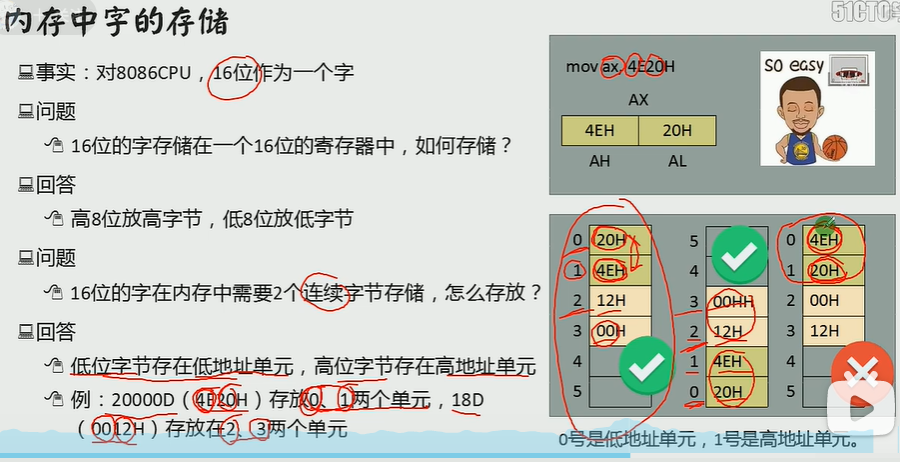
内存中字的存储

用DS和[address]实现字的传送

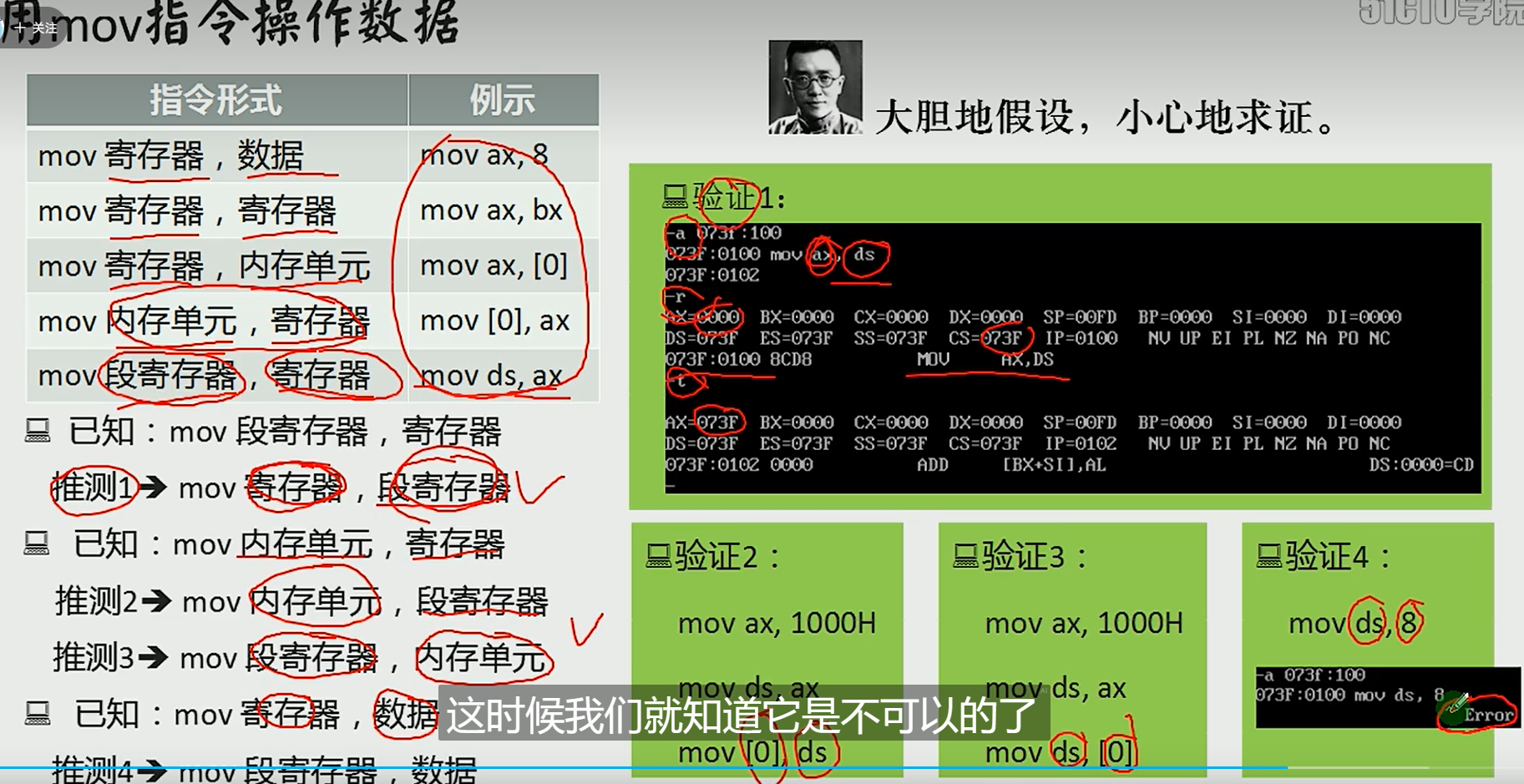
第一种方式是不能使用,
8086CPU不支持将数据直接送入段寄存器(硬件设计的问题)
数据->一般的寄存器->段寄存器
一个字节是八位
一个字是十六位
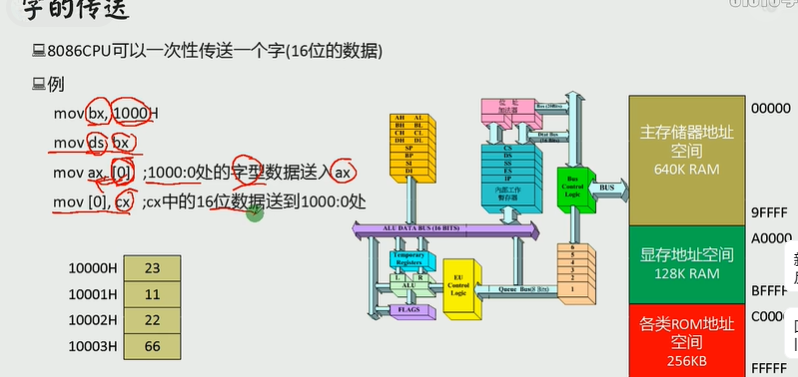
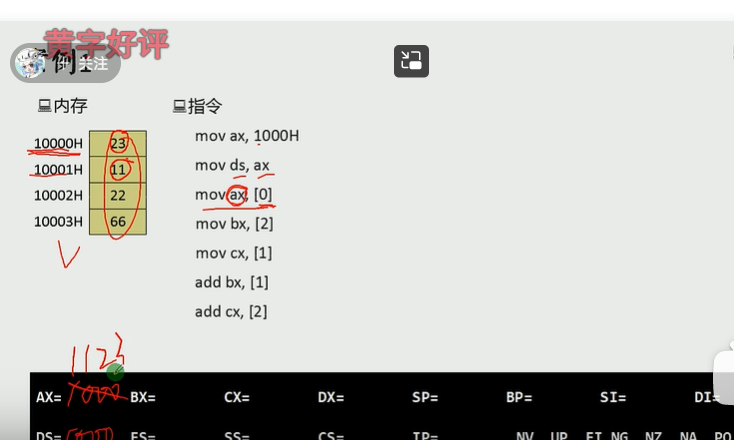
10000h是低位,10001h是高位
ax保存的数据是字型的数据
所以10000h保存的字型的数据是1123
10001h对应2211
第三条指令 使ax=1123
后面的指令同理
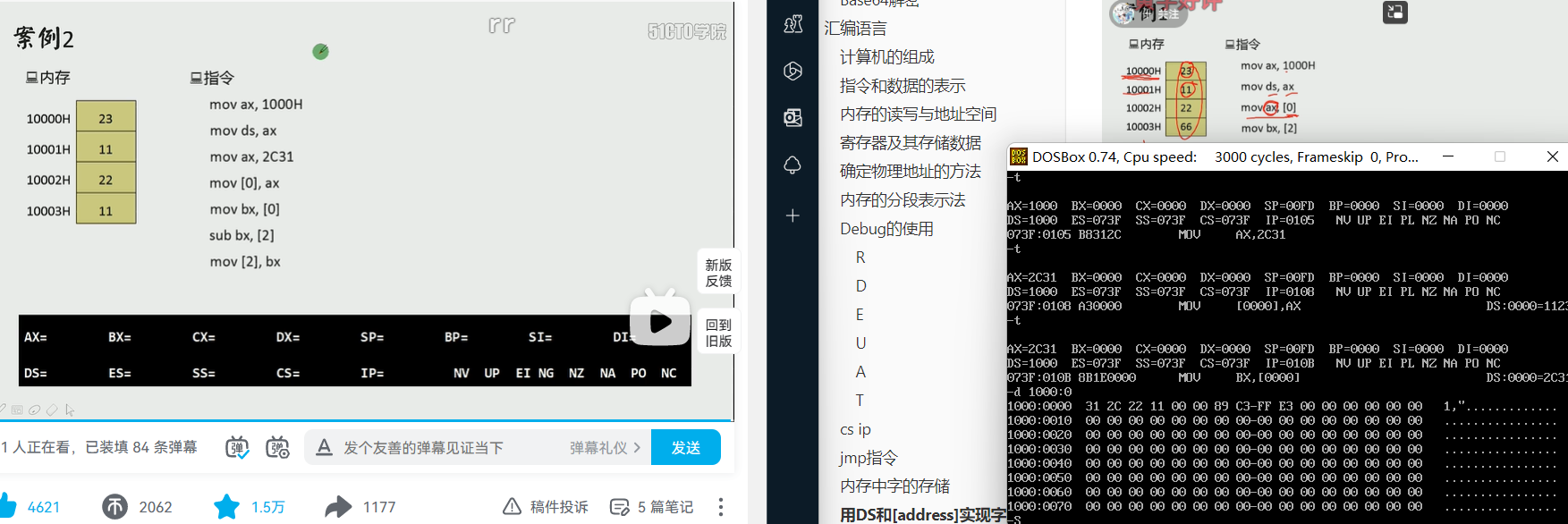
DS与数据段

累加数据段中的前三个单元数据
1 | mov ax,123bh |
累加前三个字型数据
1 | mov ax,123bh |
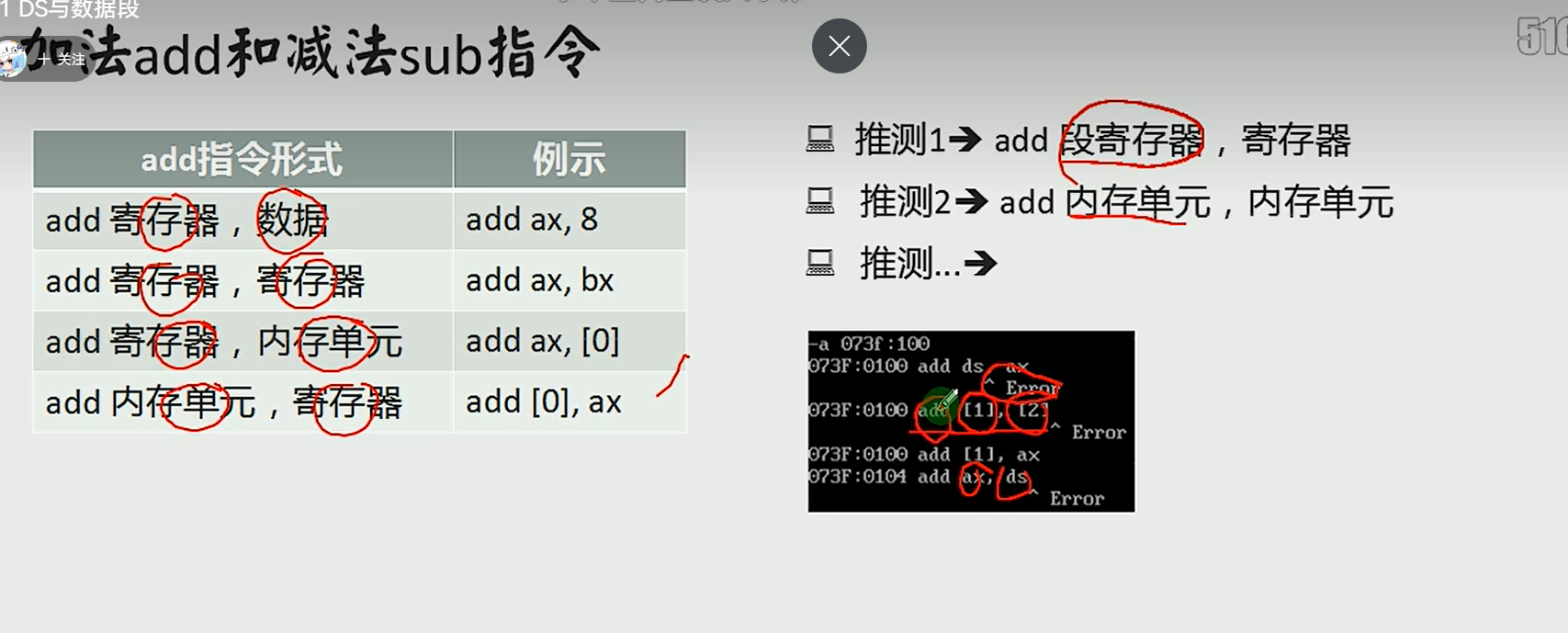
段寄存器不参与add

栈
后进先出
有两个基本操作:
入栈和出栈
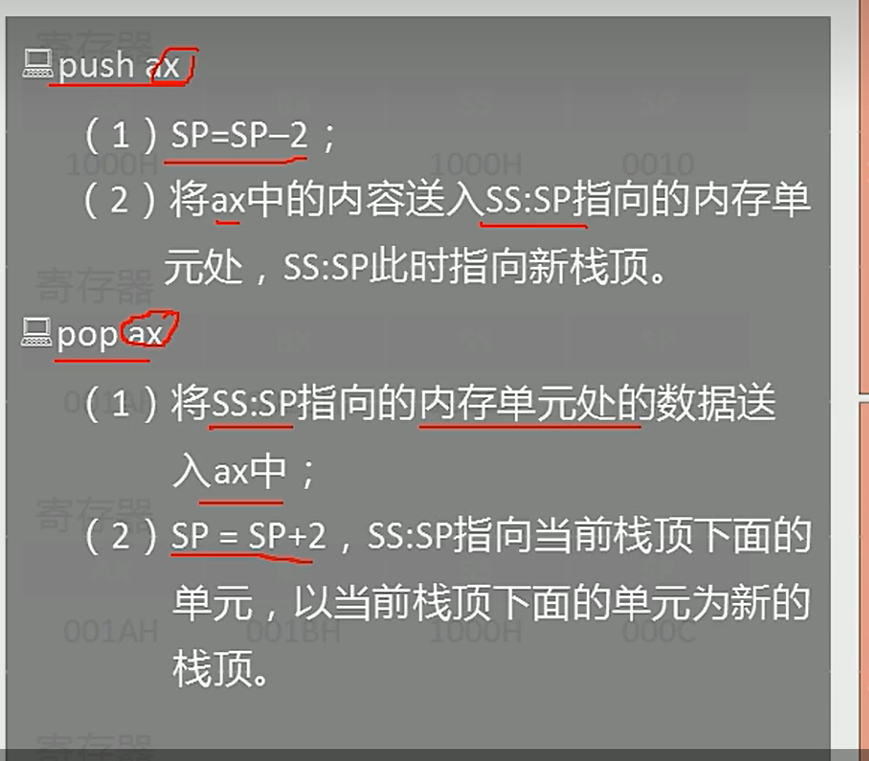
1.先将数据值赋值,内存本身数据还存在。2.赋值之后,指针再向下移动,sp+2

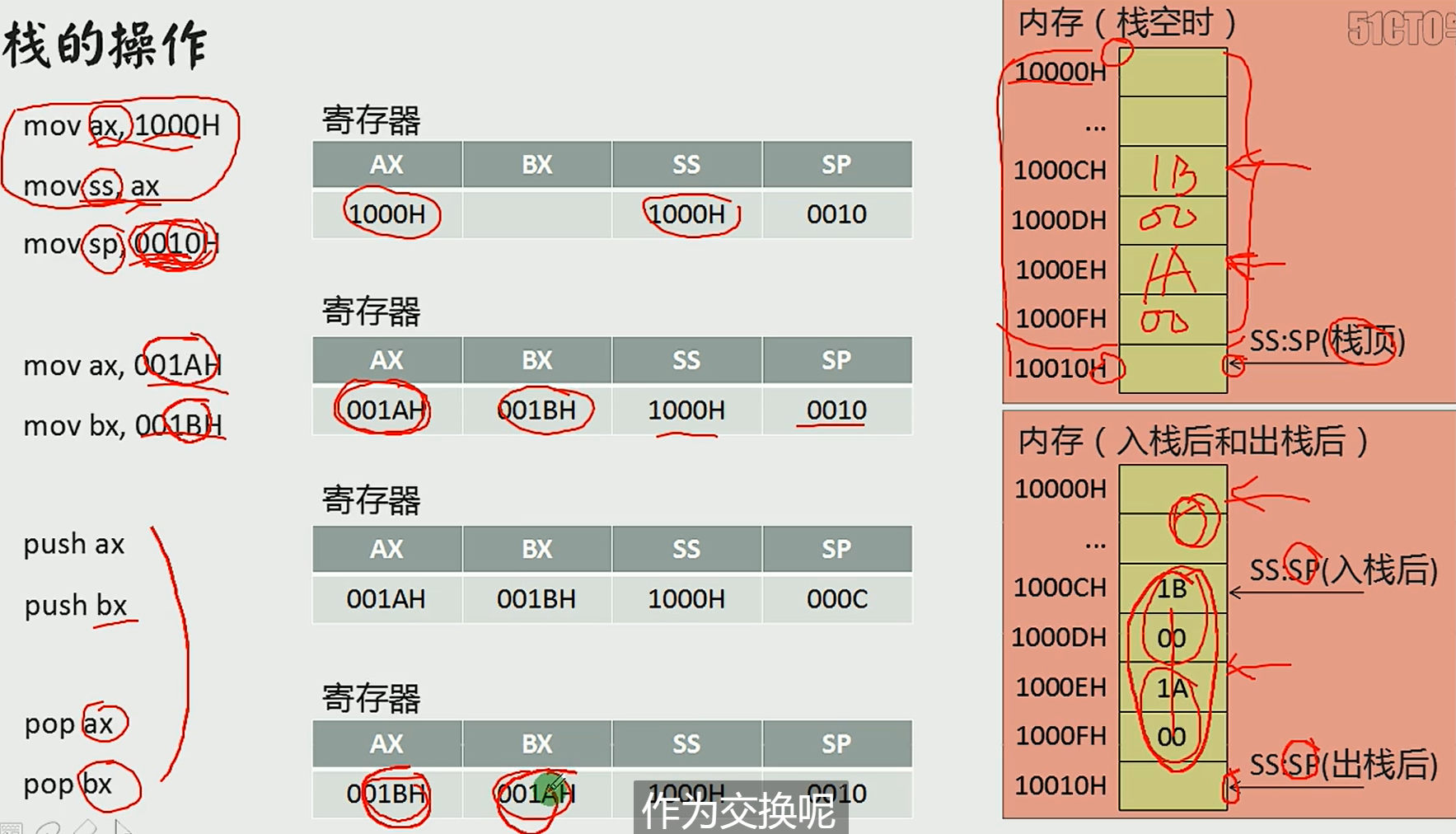
ax和bx的值发生交换


cpu不检查越界

关于段的总结
四个十六进制位=16个二进制位=2^16-1
物理地址:段地址*16+偏移地址
编程时,可以根据需要将一组内存单元定义为一个段
可以将起始地址为16的倍数(十六进制左移一位,最后一位肯定是零),长度为N(N<=64k)的一组地址连续的内存单元,定义为一个段
讲一段内存定义为一个段,用一个段地址指示段,用偏移地址访问段内的单元

**ds,es,ss作为段寄存器都可以用中转寄存器赋值,不能直接将数据mov进去,在不用r指令直接修改寄存器内容的情况下,cs段寄存器只能通过jmp等来操作,sp寄存器比较特殊可以直接mov数据. **
用汇编语言编写第一个程序
1 | assume cs:codesg |
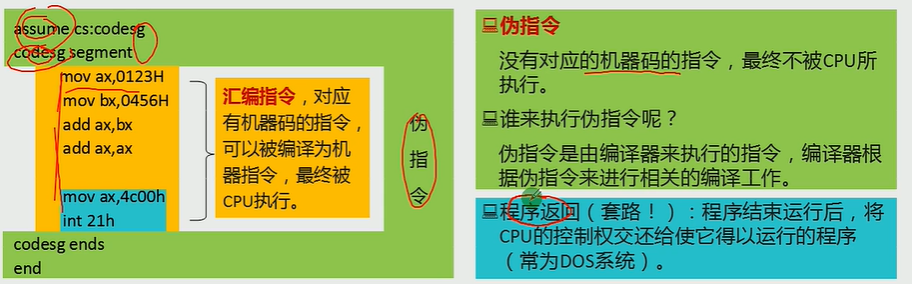
伪指令让编译器来工作

;后面全是注释
编程求2*3
1 | asuume cs:abc ;段与寄存器关联 |

由源程序到程序运行
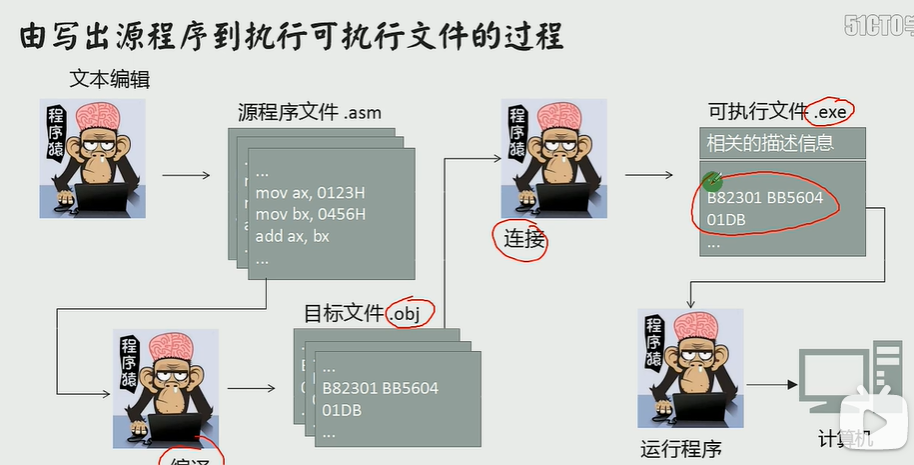
在vscode环境下
保存程序后打开dos环境
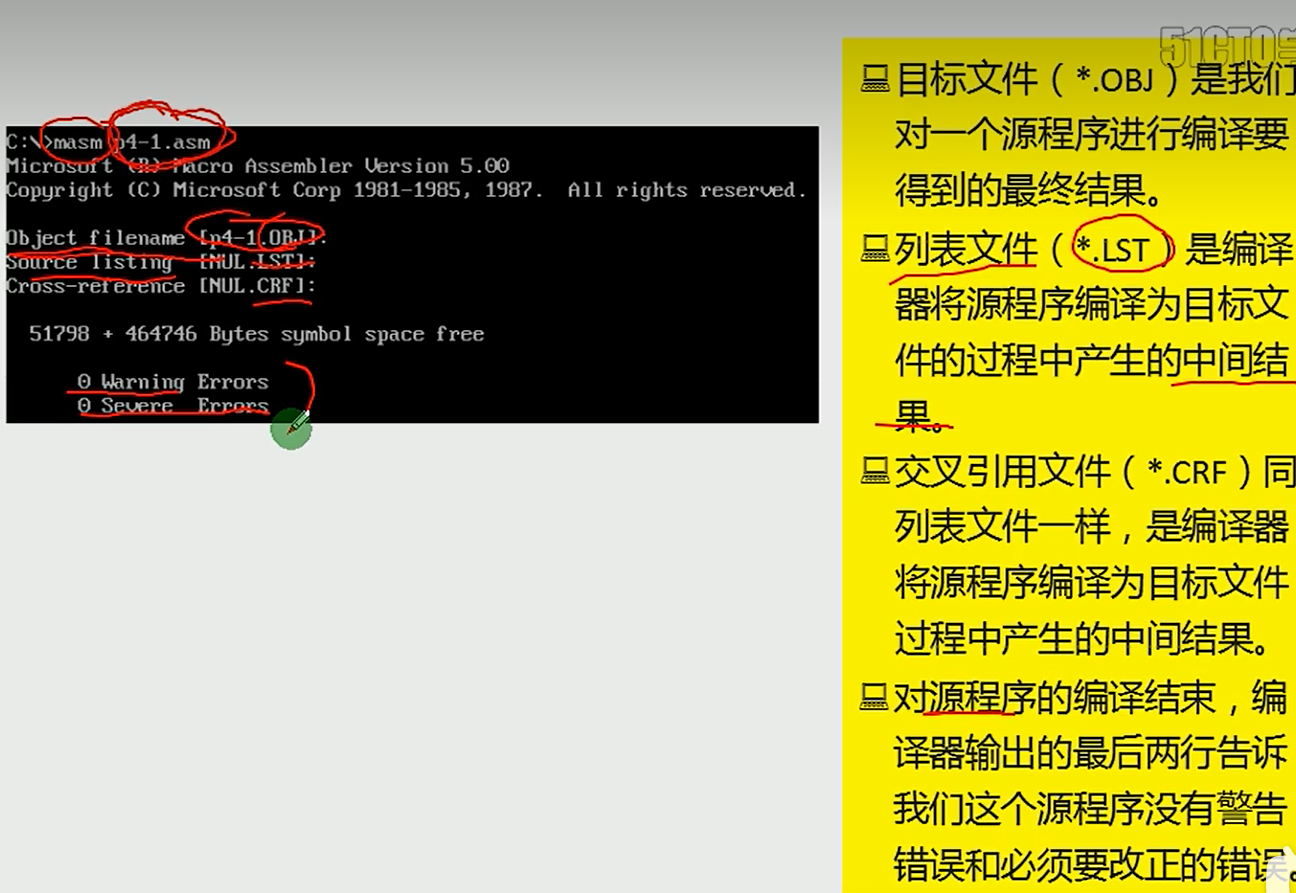
masm test.asm
就会编译

link 文件名
用debug跟踪程序的运行